LD7084 Assignment Sample – Database and Analytics Principles 2023
Introduction
A read-only technology that maintains historical information on corporate indicators including revenue productivity as well as supply quantities is an “analytic database” often known as an “analytical database” (Weinshall et al. 2020). An “analytic database” is used by industry analyzers, business administrators, as well as other employees to execute requests or even results. The information is modified frequently to incorporate the most recent activity information from a company’s operational infrastructure. An “analytic database”, which is usually a component of a “data warehouse or data mart”, is created particularly to serve BI or business intelligence as well as advanced analytics. This distinguishes its structure and functional, operational, and maybe even “online transaction processing database”, which it had been using to process transactions like placing orders as well as other software products (Weinshall et al. 2020). While payment processing systems can enable information warehousing and business intelligence operations, analytic database providers say their solutions outperform traditional relational database applications in terms of efficiency as well as flexibility. Businesses utilize “analytical databases” to store vast volumes of information to obtain insight about their organization, consumers, as well as other topics. Information in “analytical databases” is derived from a variety of resources, including “enterprise resource planning (ERP)”, “customer relationship management (CRM)”, as well as other commercial programs, as well as private information (Bellaj et al. 2020). A “data warehouse” is included in certain analysis systems and therefore is meant to be adaptable for customers who want to build custom insights or even requests. The database design, as well as query language, comprise two key elements of analysis systems. The database design is the framework for storing information. Relational data structures, in which information is kept in distinct tables and linked together as needed, and perhaps even object-oriented database schema, in which information is kept in attributes of entities as well as depicted as entities in a program (Nguyen et al. 2020). A “query language” is a standardized as well as the evaluated programming language used to get information from a “database management system (DBMS)”. The data is generally presented in the structure of a list or a series of columns, however, this has not been the case. Clients can get data through a database using a “query language” without understanding the database’s fundamental structure. SQL or “Structured Query Language” is such a well-known “query language (SQL)”. It has been applied to get data out of relational databases as well as alter it. SQL stands for an expressive software application, not a conventional one, which means that its structure is determined by the information instead of the processes used to change the information.
Section 1 – Database
ERD diagram
The connections between entity sets contained in a system are shown in an “entity-relationship diagram (ERD)”. An “entity-relationship diagram” depicts the conceptual design of database systems by describing entities, their properties, as well as the interactions between those. “Entity-relationship diagrams (ERD)” are applied to draw out a design of the database (Pan et al. 2021). The “Entity Relationship Diagram” has illustrated how various characteristics are linked. The key factors over which the relationship is built are license, booking, shipping, customer, as well as food mart or food item. The primary key, as well as the foreign key, are presented for every attribute as well as the table. With “Crow’s foot notation”, the ERD is shown here:
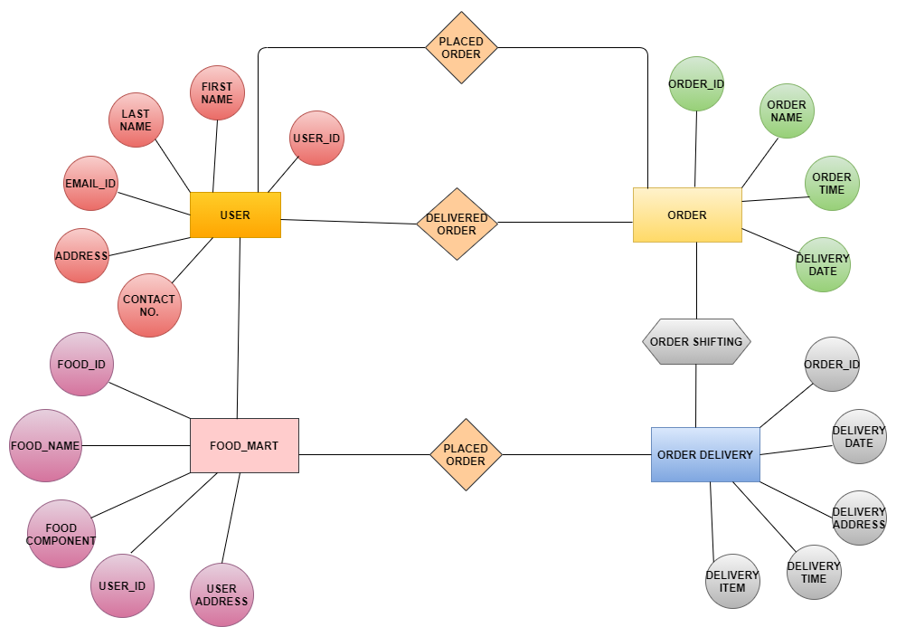

Figure 1: Entity relationship diagram
(Source: Draw.io)
“Many” or “infinite” is represented by a “crow’s foot notation”. The four forms of eigenvalues that such an entity can get from a connection are represented by these characters, which are applied in sets (Cerratto Pargman et al. 2021). The lowest is represented by the innermost component of the symbol, whereas the utmost is represented by the outermost component (nearest to the creature) (Peppler et al. 2020). “Entity-relationship diagrams” serve like a visual reference place for database architecture, as well as a tool for determining information requirements of the system across all of an organization.
Creation of database and its tables
All of the databases and SQL queries in the following chapter were created utilizing the “phpMyAdmin user interface” in xampp.
The “Customer” table’s command or query, as well as outcome, are shown below.
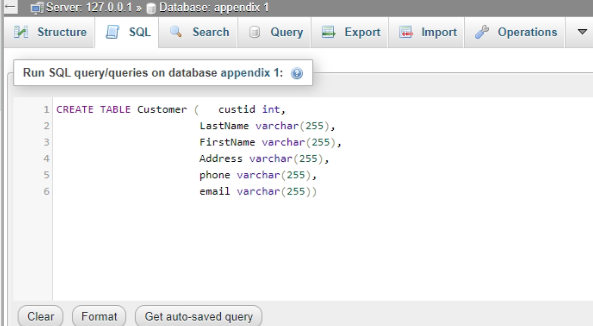
Figure 2: Creation of customer table
(Source: Xampp)
Output:
Here is the outcome of the customer table.
Figure 3: Outcome of the customer table
(Source: Xampp)
The “food mart” table’s command or query, as well as outcome, are shown below.
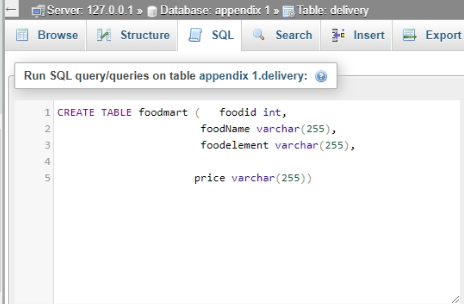
Figure 4: Creation of food mart table
(Source: Xampp)
Output:
Here is the outcome of the food mart table.
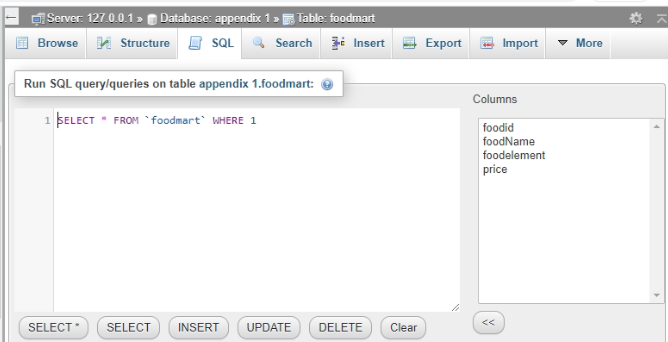
Figure 5: Outcome of food mart table
(Source: Xampp)
The “order product” table’s command or query, as well as outcome, are shown below.
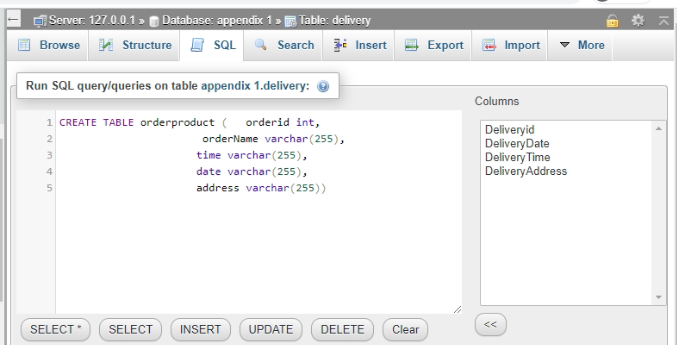
Figure 4: Creation of order product table
(Source: Xampp)
Output:
Here is the outcome of the food mart table.
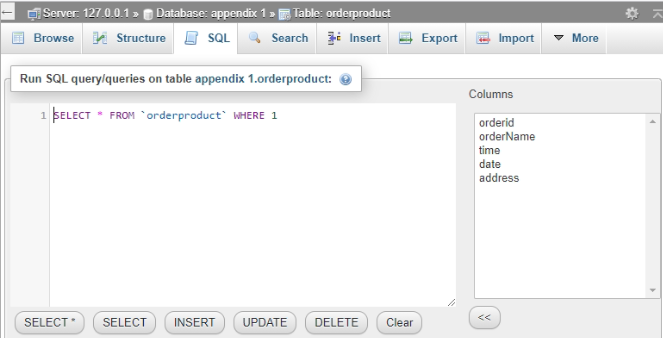
Figure 5: Outcome of the order product table
(Source: Xampp)
The “delivery stuff” table’s command or query, as well as outcome, are shown below.
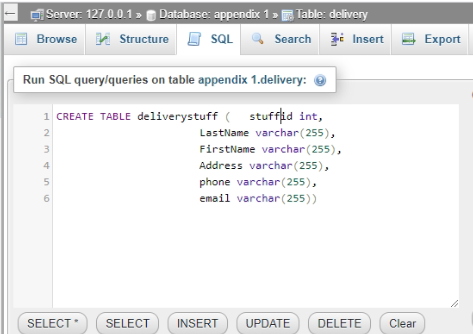
Figure 6: Creation of delivery stuff table
(Source: Xampp)
Output:
Here is the outcome of the delivery staff table.
Figure 7: Outcome of delivery stuff table
(Source: Xampp)
The “delivery” table’s command or query, as well as outcome, are shown below.
Figure 8: Creation of delivery table
(Source: Xampp)
Output:
Here is the outcome of the delivery table.
Figure 9: Outcome of the delivery table
(Source: Xampp)
The characteristics are put into the collection as the records are constructed in the database system (Kafetzopoulos et al. 2020). The images for the tables are as follows. This record is used to store information about “Customers” in the system as well as the database. The “appendix 1” dataset table’s command or query, as well as outcome, are shown below.
Figure 10: Outcome of the appendix 1 data set
(Source: Xampp)
The “appendix 2” dataset table’s command or query, as well as outcome, are shown below.
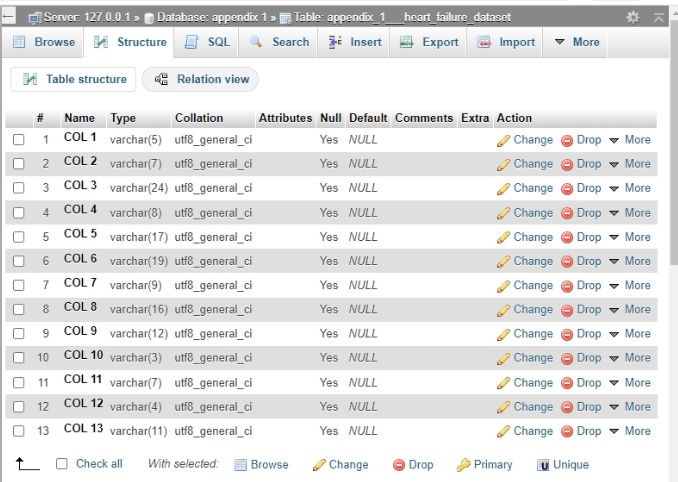
Figure 11: Outcome of the appendix 2 data set
(Source: Xampp)
The DML commands are used to insert as well as equi join data into the tables. Information is initially put into the tables using “Data Manipulation Language” commands (Schuemie et al. 2020). The outcome of the dataset is shown below.
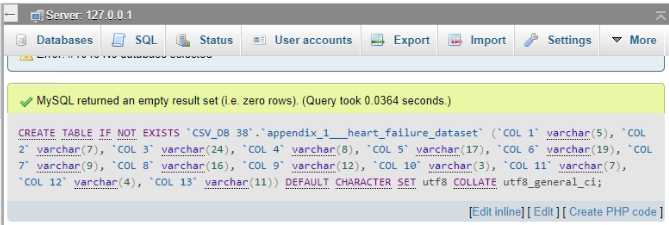
Figure 12: Outcome of the data set
(Source: Xampp)
Furthermore, utilizing the specific id “custId,” an argument statement is used to link the food mart, as well as Customer tables (Cao et al. 2020). The following is an example of a “Data Manipulation Language” statement. The outcome of the dataset is shown below.
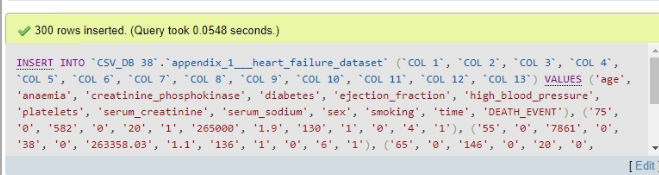
Figure 13: Outcome of the data set
(Source: Xampp)
Section 2 – Data warehouse
1. Data Warehouse Modelling
The data warehouse concept has been examined for WeDelivery, which will aid in the better administration of revenues that have already been projected in different towns around the UK or the even United Kingdom, as well as the expansion of profitability via the creation of anti-competition measures. When various competitors in the internet foodservice industry, such as Just Eat as well as DeliveryRoo, have been obtainable, this industry keeps insisting on the era of effective supervision managerial choices which will involve the shipment of a thoughtful plan again for specific managerial of the revenues evolved from the various food marts (Kara et al. 2020). The “Kimball’s four-step dimensional design process” has been implemented, which will aid in the greater creation of plans by identifying appropriate variables in the organization as well as thus assisting in the ability to understand company implications, which will result in increased revenues via the era of precise actions. The following are the many variables that were accessible during this procedure:
- Procedure selection of the business: A correct decision will be created for both the corporate strategy which will aid in the effective administration of the system and the creation of appropriate plans. The company has mostly focused on revenue generated via the transportation of food items to various households after acquiring food from various eateries (Chicaiza et al. 2020). This business has been engaged in the creation of a correct document for the eating elements requests which have already been produced by various clients via the use of a web platform, which will also be effectively achieved through all of the timely accomplishment of grocery delivery to the individual houses. This step will aid in the translation of various requests for food delivery into payments, therefore assisting in the formulation of appropriate sales concepts.
- Classification of grains: The nutrients have been recognized as the marketing patterns generated concerning the shipments produced on a yearly level for the correct growth of the clarity for both the transactions which have already been produced by the company, WeDelivery, therefore assisting in the creation of the plans consistently. Item shipments, as well as client requests, will also be properly documented concerning consumer information for improving the potential for upcoming approaches in the inevitable rise of the company across a reduction in the rivalry ratio on a wide scale via the deployment of both the star topology.
- Deciding on dimensions: At that same point, a strategy has indeed been devised for both the correct construction of dimensional selections which will aid in the creation of the “star schema framework” by generating characteristics such as customer, item, request, as well as other factors (Phillips et al. 2020). The many aspects comprise customer as well as item ids, area for various clients, and then also taking into account hotel areas for correct meal pick-up according to the agreement created with multiple food marts for the supply of foodstuffs to various clients based on web reservations.
- Assortment of facts: This step will aid in the finalization of appropriate management techniques that will aid in the formulation of precise large-scale choices. Furthermore, as revenue expertise has advanced, there has also been adequate evaluation of statistics for item creation as well as an increase in client pleasure, which will aid in a major increase in the frequency of sales revenue on a wide scale (Stair et al. 2020). Product development, as well as customer satisfaction, will contribute to an improvement in the frequency of sales for various food products, allowing this company to expand interactions by increasing delivery on a big scale.
The application of the data structure has aided in the proper identification of variables for various characteristics. “Kimball’s four-step dimensional design” method yielded this picture.
The initial stage is to determine the company goal (Bouakel et al. 2021). Because that is the greatest essential phase in “Data Modelling”, the reliability of information accessible for that procedure influences the choice of commercial purpose.
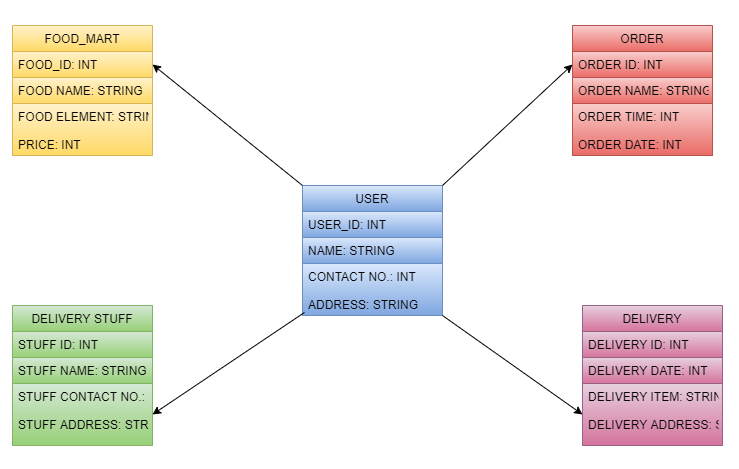
Figure 14: Star Schema
(Source: draw.io.)
The following is that many qualities have already been depicted according to the accompanying star schema diagram:
- Delivery: This feature has indeed been made accessible for several criteria such as delivery ID, delivery date, delivery item, as well as delivery address, which will aid in the production of accurate records for the many deliveries in this web platform of the business.
- Delivery stuff: This property has supplied the stuff ID, stuff name, contact info, as well as stuff address, which would be used in developing a correct history for the delivery, stuffs consistently as well as therefore assisting in monitoring the delivery stuffs for delivering appropriate food or others item delivery service to the clients.
- Food mart: The characteristics in this section have included the cost, food id, food name, as well as food element information again for food which have already been correctly recorded to aid in the appropriate identification of the requirements which have already been produced by various consumers via the use of the web platform.
- User: This has already been regarded to become the most important quality over which the whole industry is built, as well as hence the beginning point for the effective operation of such a company’s transportation service (Garcia-Arellano et al. 2020). Furthermore, the user ID, user name, contact information, as well as user address have been taken into account, which will aid in the monitoring of customer information, therefore, as a result, the establishment of a correct register for transactions of various food products in an appropriate manner.
- Order: This asset has provided the order ID, order name, order cost, order time as well as order date, which will be used to create a consistent history for the order of the products along with food items, along with assisting in tracking the order items for delivering suitable food or other item delivery service to the clients.
- Delivery stuff: This section aids in the creation of a delivery stuff record via allowing the input of the stuff name, stuff id, contact information, as well as address, that aids throughout the tracing of the delivery stuffs whereabouts for the correct accomplishment of food and various kind of product deliveries according to the needs of the clients.
In computation, “online analytical processing, or OLAP”, is a method for quickly answering multi-dimensional statistical questions. OLAP stands for a type of BI or business intelligence that includes things like data mining, relational databases, as well as report creation (Wang et al. 2020). The idea also for the usage of a storage facility is necessary for both the correct creation of the “warehouse design”. “Data Cube” has aided throughout the effective reduction of administrative needs for many dimensions of the business.
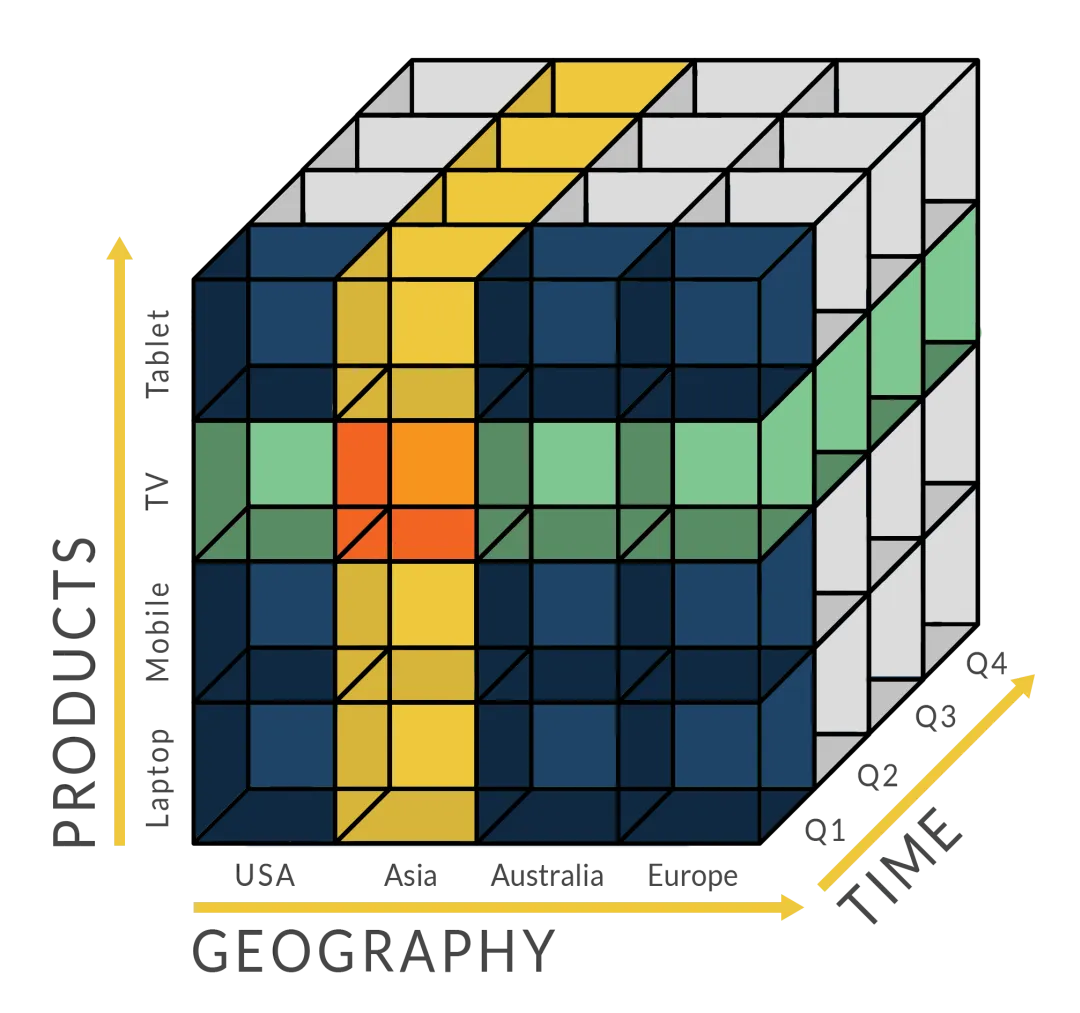
Figure 15: “OLAP or online analytical processing”
(Source: OLAP)
The use of “OLAP or online analytical processing” via the creation of information for correct insight into digital marketing, “online analytical processing” has aided in improved management consulting (Fiofanova et al. 2020). The following are the various dimensions:
- Salesperson: The decline in salesman accessibility may have a significant impact on large-scale internet shopping transactions. Maybe there is an issue with appropriate upkeep again for the supply person’s service price. As just a result, rewarding amenities must be available that can significantly aid in the expansion of sales by increasing the consistency as well as context clues of the salesman.
- Sales amount: This dimension may be useful in the evolution of the study via transactions performed across an expansion in the stage of reserving for various meals, therefore assisting in the right assessment of the rate of the revenue for both the company in an appropriate way.
- Month: There may be a high period for both the monthly whenever selling of foodstuffs via internet booking may grow, and so, therefore, good managing of request during such busy periods may aid in the growth in the revenue ratio for this business of the company (Fayyad et al. 2020). The study may be obtained by examining the variations in selling quantity throughout the period, which would aid in the creation of the appropriate findings.
- Region: This dimension can aid in the production of clarity for revenue development for various places, as well as contemplating the company’s primary center in the upcoming days. The grade of the products as well as services will improve to fulfill the expectations of the consumers promptly, therefore assisting throughout the large-scale expansion of the organization.
- Year: The use of this aspect aids in the formulation of yearly assessments, therefore, as a result, in the era of appropriate predictions for the company’s profitability level expansion via revenues.
- Products or items: The item will aid throughout the clarity of the notion for both the creation of a desire for the appropriate food product or even other items, which has resulted in a significant increase in revenue and profit (Bourgeault et al. 2021). There would be a definite evolution of the concept via evaluation of item grade, and therefore methods for increasing production efficiency to build item needs for clients would be implemented.
The rationale for using the “OLAP or online analytical processing” is that it would give concepts for developing commercial approaches such as item growth as well as customer happiness by properly managing the above-mentioned aspects. There will also be appropriate forecasts for the revenues of various food products at various times, which will aid in the creation of plans for both the elimination of commercial difficulties in the current environment.
Section 3 – Data Mining
Stage of data preparation
Every action to create the ultimate datasets from either the initial basic information for “data preparation” is done within phases of both the “data preparation”, as per the “CRISP-DM,” that refers to “Cross Industry Standard Process for Data Mining” (Nagarathinam et al. 2021). It is conceivable that “data preparation” operations will be performed without regard to any particular sequence.”
“Data mining” is a technique for examining raw information in an attempt to find connections as well as establish links between information in terms to solve issues.
“Cross Industry Standard Process for Data Mining” has been used to process the information in this study, out of all the usual techniques. The much more essential aspect of this paradigm is information comprehension. Because although the provided information in the data collection must be processed in such a way that no errors are created throughout machine learning or even artificial intelligence.
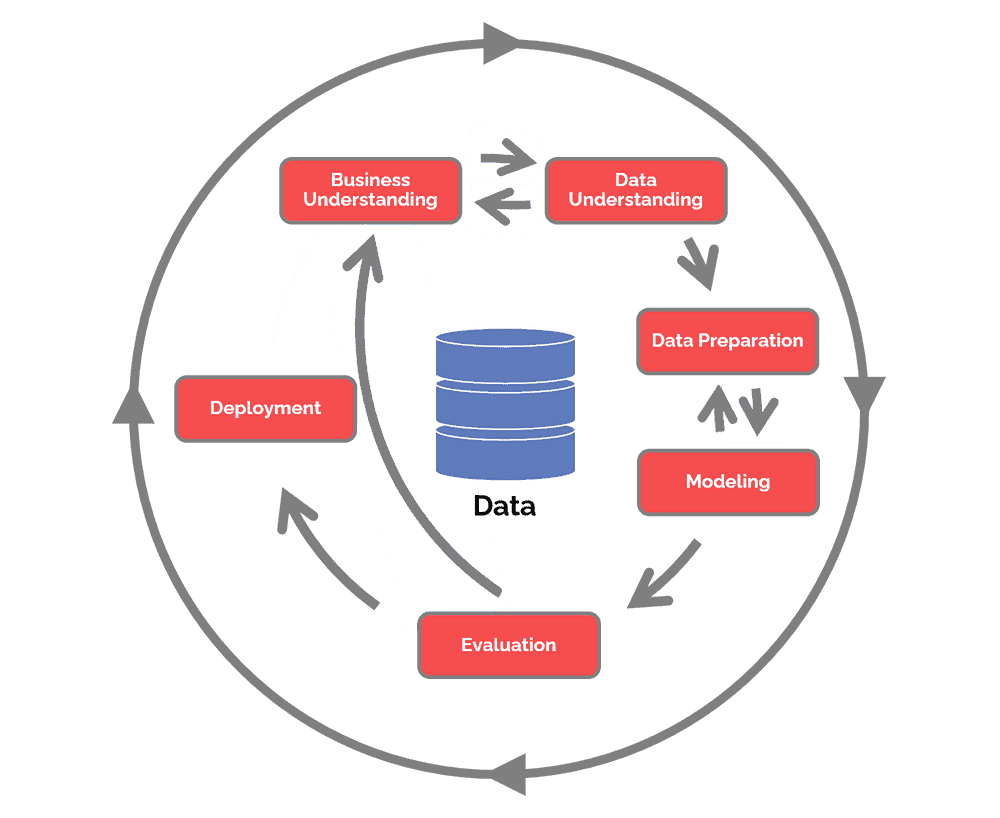
Figure 16: “Cross Industry Standard Process for Data Mining”
(Source: www.data science-pm)
The “Cross Industry Standard Process for Data Mining life cycle model”, which would be extensively utilized by all organizations, is depicted in the diagram ahead. For both the aim of data processing, it outlines several steps of a recurrent structure. In real-time, those stages may not be maintained logically. It is capable to bring out the stages in a specific way, as well as “data analysts” can go back as well as forth between them as needed. Two-way links are connecting multiple positions in the previous diagram. These rounds will be required depending on the kind of partnerships as well as information to refine the projected information or even just improve the design’s sensitivity and specificity.
A data collection of the heart failure people was provided for this research, as well as it was suggested that the information be prepared for “data analysis” in the “data preparation” phases to use the “Cross Industry Standard Process for Data Mining life cycle model”.
Data preparation stages
“Data understanding” would be the initial step in the procedure of data preparation, as seen in the “Cross Industry Standard Process for Data Mining” diagram. Furthermore, information from either the heart problems data collection will be analyzed to learn more about the information, detect data integrity concerns, as well as also get preliminary conclusions. This would be accomplished by examining every one of the values in each column, the types of features, informative visualization as well as for analytics, null values, or even conflicting data sets, among other things.
As previously said, data preparation tasks are divided into several steps. The following are some of them:
Selection of the data: Initially and foremost, the criterion for selection of the data would be revisited. To pick information, the supplied “heart failure data set” would be applied. The use of sampling approaches will indeed be taken into account. More information would be gathered as needed.
Construction of the data: The dataset’s properties will be generated. It would be necessary to get some prior information. The elements that are lacking will be created.
Cleaning of the data: Hazardous information would be fixed, deleted, or avoided. Working with either the dataset’s different characteristics. Identifying absent variables.
Reduction of the data: This procedure is mostly used to reduce null values. When a null or NAN result is found inside this data collection, it will be substituted by the computed mean of any of the values in the rows (Yao et al. 2020). Alternatively, the “null value” would be substituted via the mean of the values on both edges (from separate rows) of the “null value”, which would be computed.
Scaling of the feature: Data preparation is incomplete without scaling of the feature. It is a method for normalizing the unique features of a set of information. Throughout data preparation, it is used to manage drastically variable orders of magnitude, categories, or quantities.
There seems to be a row called “platelet” inside the supplied dataset, which provides highly high-value metrics for patients with heart failure (Herrada et al. 2020). Those variables would be tough to acquire throughout machine learning or artificial intelligence as well as will require a huge amount of memory. Each information in that row would be placed on a modest scale to reduce storage use as well as first training.
Integration of the data: Bringing assets together as well as archiving the results of records as well as new tables.
Preparation of data is crucial: Again for the creation of valid and reliable designs that are extremely practical and reliable, efficient “data preparation” is critical. It is critical to identify data issues early on to reduce incorrect projections (Dinov et al. 2020). Whatever analysis model’s accuracy is highly dependent on the integrity of both the information it collects. Valuable data gives crucial views, allowing for better decision-making as well as operating excellence inside of the company (Martinov et al. 2020). Data preparation is done carefully as well as methodically could reduce a huge amount of time, effort, as well as money.
As a result, the research participants have done their effort to produce a trustworthy dataset again from supplied information, which would be required for identifying patient fatalities due to heart failure.
Machine learning methods for predicting heart failure-related mortality in individuals
To forecast as well as construct patterns, machine learning techniques are employed. These techniques are applied to create risk estimates for heart failure that assess the severity of the illness as well as the likelihood of outcomes such as sudden cardiac arrest, all-cause morbidity, and hospitalization.
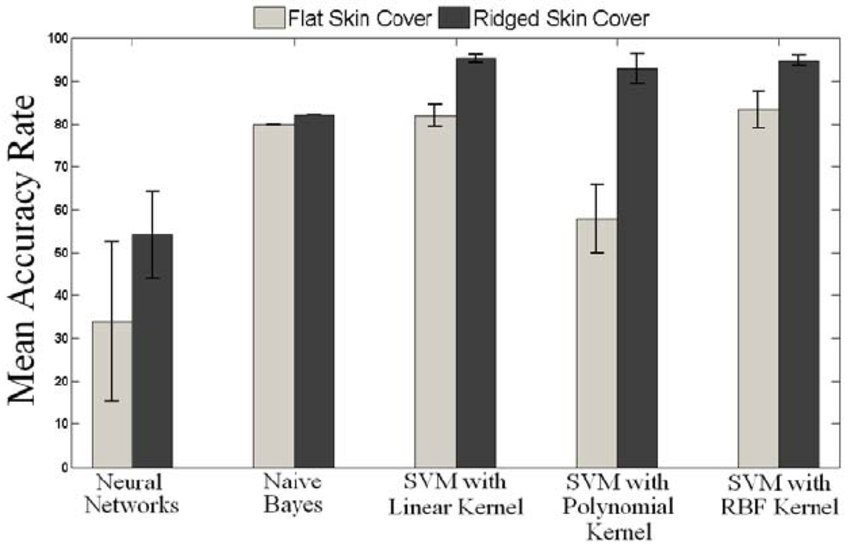
Figure 17: Machine learning techniques are shown as a bar graph
(Source: www.researchgate)
Justification for the decision
Decision trees have open to interpretation as well as understandable characteristics, and they can quickly tell why an individual will be at a huge risk characteristic of heart problems and lead the decrease of following hazards. In comparison to artificial intelligence techniques, decision trees offer an accuracy characteristic that is quite valuable. That is the nature of an “artificial neural network with a black box” (Paryanto et al. 2020). Following the exposure of randomized information specimens to various decision tree techniques, the ensembles of “decision trees” use opinions to identify the category while generating forecasts.
Random forests outperform other methods in big datasets with missing information. Every one of the sets of data characteristics, including age, creatinine phosphokinase, anemia, serum creatinine, high blood pressure, smoking, sex, DEATH EVENT, as well as time would be used to forecast heart failure morbidity utilizing artificial intelligence (Ceccucci et al. 2020). It would still be disputed if most of the major risk variables causing heart failure would be correctly predicted.
Section 4 – Business Intelligence
Dashboard
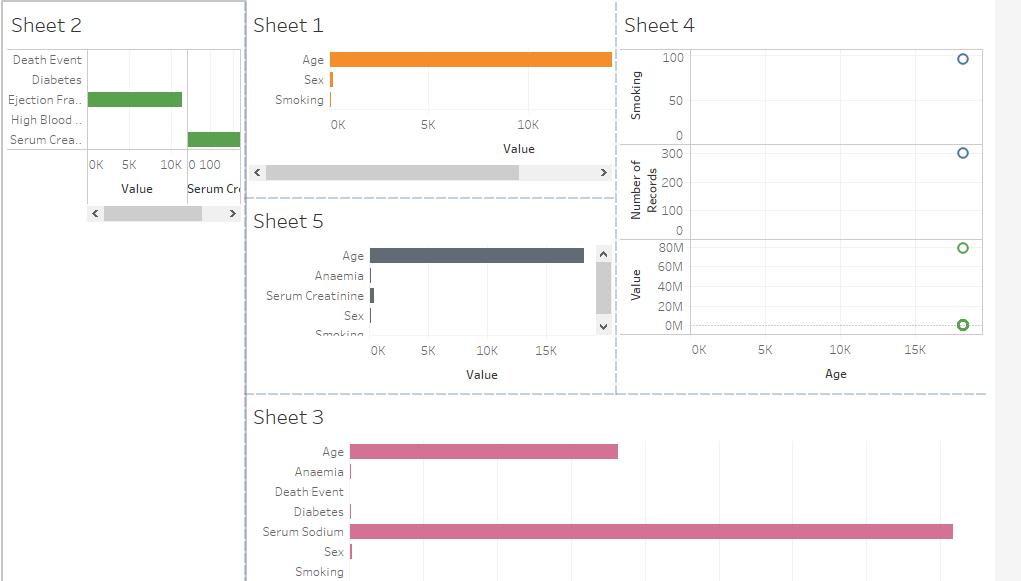
Figure 18: Dashboard design
(Source: Tableau)
Section 5 – NOSQL Database
Introduction
A database’s “relational database” is an important element. It makes use of a platform design that enables information to be generated as well as viewed in connection to certain other information items in the platform. Data is often split into multiple sections in a “Relational Database” (Raban et al. 2020). In contrast to the table relationships of “relational databases,” a “NoSQL database” includes a method for database design resilience as well as restoration. As database administrators, users must understand which systems are acceptable, and this will assist the management in making a decision. This chapter discusses which systems are appropriate for such a start-up company. The requirements are mentioned, and they clearly describe the advantages of using a certain database platform throughout this start-up company.
Choice Factors of database
For some years, “Relational Database Management Systems” (RDBMS) are already in service. When models of data are basic as well as stable, they have typically proven effective. In able to handle the rapid expansion of the volume of data as well as the increasing variety of “data structures,” the “SQL relational database” has fundamentally become less suited (Udgave et al. 2020). The “NoSQL databases” have been prominent in recent generations as a much more flexible, cost-effective, or even expandable replacement to the “Standard SQL database”. A “complex schema” allows “unstructured files” to be used in “NoSQL databases.” After that, corporate designers may design an application without having to describe the schema beforehand.
Conclusion
From such a portion of the study, it is clear that the “NoSQL database” is superior to that same RDBMS for just any new business. Because databases in NoSQL are not connected, whatever start-up firm should use it instead of RDBMS. Well with existing techniques, the “database” is frequently extensible laterally. The content of the database is indeed key-valued. As a result, NoSQL is appropriate for unorganized data.
Reference list
Journals
Bellaj, M., El Hibaoui, A. and Bendahmane, A., 2020. Big Data Analytics for Preschool (No. 4250). EasyChair.
Bouakel, M. and Zerbout, A., 2021. Perspectives of Big Data Analytics’ Integration in the Business Strategy of Amazon, Inc. In Big Data Analytics (pp. 201-220). Apple Academic Press.
Bourgeault, I.L., Chamberland-Rowe, C. and Simkin, S., 2021. Co-developing an integrated primary care workforce planning approach at a regional level: overarching framework and guiding principles. Human Resources for Health, 19(1), pp.1-6.
Cao, W., Gao, Y., Li, F., Wang, S., Lin, B., Xu, K., Feng, X., Wang, Y., Liu, Z. and Zhang, G., 2020, June. Timon: A Timestamped Event Database for Efficient Telemetry Data Processing and Analytics. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (pp. 739-753).
Ceccucci, W., Jones, K., Toskin, K. and Leonard, L., 2020. Undergraduate Business Analytics and the Overlap with Information Systems Programs. Information Systems Education Journal, 18(4), pp.22-32.
Cerratto Pargman, T., McGrath, C., Viberg, O., Kitto, K., Knight, S. and Ferguson, R., 2021. Responsible learning analytics: Creating just, ethical, and caring la systems. In LAK21, virtual conference, 12-16 April, 2021 (pp. 331-335). SoLAR.
Chicaiza, J., Cabrera-Loayza, M.C., Elizalde, R. and Piedra, N., 2020, January. Application of data anonymization in Learning Analytics. In Proceedings of the 3rd International Conference on Applications of Intelligent Systems (pp. 1-6).
Dinov, I.D., 2020. Modernizing the methods and analytics curricula for health science doctoral programs. Frontiers in public health, 8, p.22.
Fayyad, U. and Hamutcu, H., 2020. Toward foundations for data science and analytics: A knowledge framework for professional standards. Harvard Data Science Review, 2(2).
Fiofanova, О.А. and Toporkova, E.S., 2020. International Analysis of National Databases of Educational Statistics and Analysis of the Technologies’ Educational Data in Countries of the World. Journal of Advanced Pharmacy Education & Research| Jul-Sep, 10(3), p.91.
Garcia-Arellano, C., Roumani, H., Sidle, R., Tiefenbach, J., Rakopoulos, K., Sayyid, I., Storm, A., Barber, R., Ozcan, F., Zilio, D. and Cheung, A., 2020. Db2 event store: a purpose-built IoT database engine. Proceedings of the VLDB Endowment, 13(12), pp.3299-3312.
Herrada, R.I., Baños, R. and Alcayde, A., 2020. Student Response Systems: A Multidisciplinary Analysis Using Visual Analytics. Education Sciences, 10(12), p.348.
Kafetzopoulos, D., Stylios, C.D. and Skalkos, D., 2020. Managing Traceability in the Meat Processing Industry: Principles, Guidelines and Technologies. In HAICTA (pp. 302-308).
Kara, K., Hagleitner, C., Diamantopoulos, D., Syrivelis, D. and Alonso, G., 2020, August. High Bandwidth Memory on FPGAs: A Data Analytics Perspective. In 2020 30th International Conference on Field-Programmable Logic and Applications (FPL) (pp. 1-8). IEEE.
Martinov, G.M., Kovalev, I.A. and Chervonnova, N.Y., 2020. Development of a platform for collecting information on the operation of technological equipment with the use of Industrial Internet of Things. In IOP Conference Series: Materials Science and Engineering (Vol. 709, No. 4, p. 044063). IOP Publishing.
Nagarathinam, T., Elangovan, V.R., Obaid, A.J., Akila, D. and Tuyen, D.Q., 2021, July. E-Learning in Data Analytics on Basis of Rule Mining Prediction in DM Environment. In Journal of Physics: Conference Series (Vol. 1963, No. 1, p. 012166). IOP Publishing.
Nguyen, A., Tuunanen, T., Gardner, L. and Sheridan, D., 2020. Design principles for learning analytics information systems in higher education. European Journal of Information Systems, pp.1-28.
Pan, S.L., Li, M., Pee, L.G. and Sandeep, M.S., 2021. Sustainability design principles for a wildlife management analytics system: An action design research. European Journal of Information Systems, 30(4), pp.452-473.
Paryanto, P., Munyensanga, P., Indrawan, H. and Cahyo, N., 2020. Application of power plant 4.0: Process digitalization and challenges. Rotasi, 22(1), pp.55-61.
Peppler, K., Huang, J., Richey, M.C., Ginda, M., Börner, K., Quinlan, H. and Hart, A.J., 2020. Key principles for workforce upskilling via online learning: a learning analytics study of a professional course in additive manufacturing. arXiv preprint arXiv:2008.06610.
Phillips, T. and Ozogul, G., 2020. Learning analytics research in relation to educational technology: Capturing learning analytics contributions with bibliometric analysis. TechTrends, 64, pp.878-886.
Raban, D.R. and Gordon, A., 2020. The evolution of data science and big data research: A bibliometric analysis. Scientometrics, 122(3), pp.1563-1581.
Schuemie, M.J., Ryan, P.B., Pratt, N., Chen, R., You, S.C., Krumholz, H.M., Madigan, D., Hripcsak, G. and Suchard, M.A., 2020. Principles of Large-scale Evidence Generation and Evaluation across a network of databases (LEGEND). Journal of the American Medical Informatics Association, 27(8), pp.1331-1337.
Stair, R. and Reynolds, G., 2020. Principles of information systems. Cengage Learning.
Udgave, A. and Kulkarni, P., 2020. TEXT MINING AND TEXT ANALYTICS OF RESEARCH ARTICLES. PalArch’s Journal of Archaeology of Egypt/Egyptology, 17(6), pp.4483-4489.
Wang, W.Y., Li, P., Lin, D., Tang, B., Wang, J., Guan, Q., Ye, Q., Dai, H., Gao, J., Fan, X. and Kou, H., 2020. DID Code: A Bridge Connecting the Materials Genome Engineering Database with Inheritable Integrated Intelligent Manufacturing. Engineering, 6(6), pp.612-620.
Weinshall, K. and Epstein, L., 2020. Developing High‐Quality Data Infrastructure for Legal Analytics: Introducing the Israeli Supreme Court Database. Journal of Empirical Legal Studies, 17(2), pp.416-434.
Yao, J.J., Cook, S.B., Gee, A.O., Kweon, C.Y. and Hagen, M.S., 2020. What is the survivorship after hip arthroscopy for femoroacetabular impingement? A large-database study. Clinical Orthopaedics and Related Research®, 478(10), pp.2266-2273.
Know more about UniqueSubmission’s other writing services:
