COMP1804 Applied Machine Learning Assignment Sample
Module code and Title: COMP1804 Applied Machine Learning Assignment Sample
Introduction
Linear regression is basically kind of a machine learning algorithm on the basis of supervised learning. In addition, linear regression generally performs several kinds of regression tasks. Additionally, the models of linear regression basically target the forecasting value on the basis of the independent variables. More than that, linear regression is commonly applied for discovering the connection among predictions as well as variables.

However, various kinds of models based on regression simply vary the types of connection among the independent variables and dependent variables they are in the view as well as the amount of independent variables getting applied. In this assignment the exploratory data analysis technique is also used. In this assignment it will discuss the brief analysis of the linear regression from the proposed dataset. In this assignment for the analysis, there are several kinds of libraries that are used such as the pandas, numpy, seaborn and matplotlib. After appropriately checking the dataset then the analysis process starts.
Ethical Discussion
Before starting the analysis of the regression first it imports some libraries. In this assignment pandas, numpy, seaborn and matplotlib libraries are used. After uploading the data set in the google colab first it is required to check that the data is clear or not. Cleaning the data is the procedure of eliminating or adjusting the corrupted, incorrect, duplicate, incorrectly formatted or some kinds of incomplete data within the sets of data. In addition, while combining several kinds of data sources, there are huge possibilities and also chances for the data to be mislabeled or duplicated.
As well, if the data is appropriate, results as well as the algorithms are not reliable nonetheless the datasets may look proper. As well, there is no kind of appropriate path to authorize the appropriate phases in the process of cleaning the data just because the procedures will differ from one dataset to another. Nevertheless, this thing is essential to template establishment for the proposed process of data cleaning.
The data ethics simply designate as well as attachto not only the principles as well as values where the laws of personal data protection and the rights of the human are based. However, this thing is actually genuine honesty as well as transparency as the sets of data management is worried. As well, the basic purpose of the ethics is to generate some kinds of privacy boosting objects and also some kinds of privacy by the infrastructure and design. More than that, the data ethics is simply one of the most essential and valuable aspects in the process of analyzing the data. As well, the ethics is significant just because there should be some kind of “universal framework” for what associations can as well as what associations cannot perform in addition to the data they gathered from outside. More than that, for this assignment two methods are chosen.
The first one is the EDA which is also known as exploratory data analysis and on the other hand the other one is the linear regression. In addition, the EDA which is also known as exploratory data analysis simply address to the crucial procedure of working the final examination of the data for the development of new structures or patterns, to test hypothesis, to spot anomalies as well as also to check some kinds of assumptions in addition to the assist of graphical representation and summary statistics. On the other hand linear regression is the machine learning supervised model in which the developed model simply discovers the accurate linear among the dependent variable and independent variable.
As well, linear regression generally performs several kinds of regression tasks. Additionally, the models of linear regression basically target the forecasting value on the basis of the independent variables. So, these two methods are generally used to detect errors in the database, several kinds of outliers and to recognize various kinds of patterns in the database and also for discovering the connection between forecasting and various types of variables.
Methods and Dataset preparation
In this assignment, first the proposed data set uploads in the platform of google colab. In addition, after loading the entire dataset in the platform of google colab it checked the rows of the proposed data set. In the proposed data set it has simply five rows. The respective review id of the rows are, iclr_review_0000, iclr_review_0002, iclr_review_0001, iclr_review_0003 and the last one is the iclr_review_0004.
More than that, after getting the rows from the proposed dataset it simply found that there was some kind of characteristic information of the dataset. In addition, the platform google colab simply analyzes the respective characteristics information of the proposed dataset. From the analysis of the datasets characteristic it can be stated that there are several kinds of data in the overall dataset. Basically from the analysis of the dataset it can be found that there are generally two kinds of data, the first one is object type as well as the second one is the float64 type.
More than that, from the analysis of the proposed data set it simply found that there are several types of value in each row of the dataset. In the entire dataset there are generally several kinds of value which indicates that the dataset is blank in some rows of cells. Additionally, there are just two times 6118 entries in the dataset.
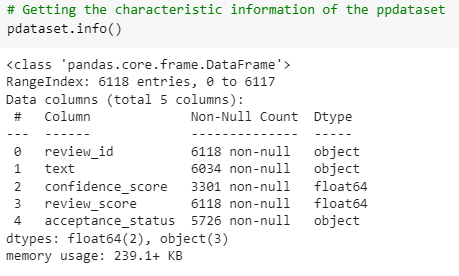 Figure 1: Characteristics information of the dataset (Source: Self-created in Google Colab)
Figure 1: Characteristics information of the dataset (Source: Self-created in Google Colab)
From the analysis of the dataset it can be stated that the mean value of the dataset is about the confidence_score 3.80 and the review_score 4.69. Whereas the max value of the dataset is about for the confidence_score 5.00 and the review_score 10.00. As well, the standard value of the dataset is about the confidence_score 0.82 and the review_score 2.16. The minimum value of the dataset is about the confidence_score 1.00 and the review_score -1.00.
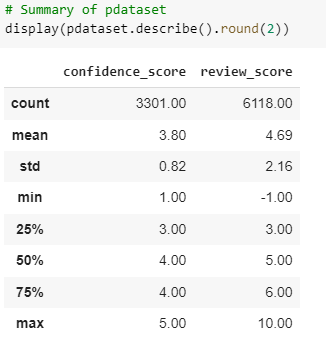 Figure 2: Summary of dataset (Source: Self-created in Google Colab)
Figure 2: Summary of dataset (Source: Self-created in Google Colab)
In addition, while checking the null value of the dataset it clearly found that there are just two rows where no null value was found. It simply means that those two are appropriate. Whereas on the other hand from the dataset it was also found that there were three brown where null values are found which means the data rows are not appropriate.
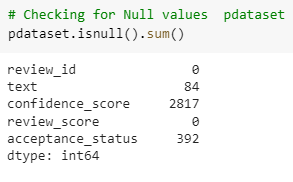 Figure 3: Null values checking (Source: Self-created in Google Colab)
Figure 3: Null values checking (Source: Self-created in Google Colab)
As the entire dataset generally carries vast amounts of null values that is why the dataset is required to be dropped. Dropping a database means the database deletes from the respective server as well as also eliminates the “physical disk files” applied by the overall dataset. More than that, from the proposed dataset just because of the null values it required to be dropped. In addition, to display the null values appropriately in the database the Heatmap is used.
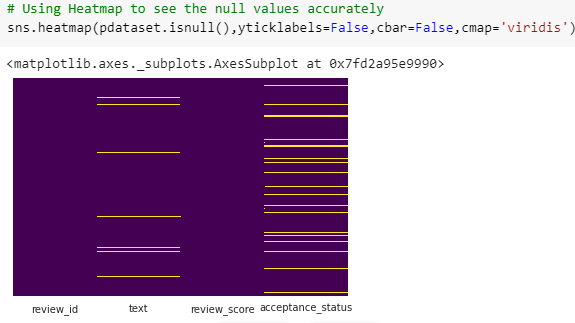 Figure 4: Adding heatmap in the database (Source: Self-created in Google Colab)
Figure 4: Adding heatmap in the database (Source: Self-created in Google Colab)
From the analysis of the database after applying the heatmap it clearly showed that there are some kinds of null values that are also present in the database. In addition, these all null values are also required to be dropped.
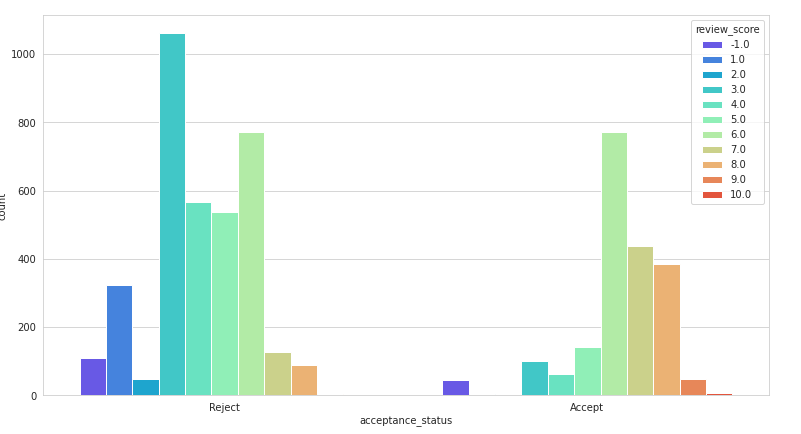 Figure 5: Plotting bars for the acceptance and rejection (Source: Self-created in Google Colab)
Figure 5: Plotting bars for the acceptance and rejection (Source: Self-created in Google Colab)
This plotting bar snip that has been attached simply displays the acceptance as well as rejection on the basis of review score. In addition, in this assignment for the acceptance status it simply chose accept or reject. More than that, to display the review score it simply assumes the integer number between ten to one. As well, it was also assumed that if the integer score is higher than five then the status should be accepted whereas if the integer score is not higher than five then the chartreuse should be rejected.
As it previously discussed, in the entire database there were vast amounts of null values. In addition, to delete the null values the database again required to be dropped.
 Figure 6: Dropping null values again (Source: Self-created in Google Colab)
Figure 6: Dropping null values again (Source: Self-created in Google Colab)
After deleting all the respective columns of the null values the database checked again for the nul;l values. After dropping the database again and checking the database it can be clearly stated that there are no null values present in the proposed database.
 Figure 7: Rechecking the null values (Source: Self-created in Google colab)
Figure 7: Rechecking the null values (Source: Self-created in Google colab)
In the above snip it simply displays the results of the null values after dropping again. After dropping the dataset again there were no null values found so the database is now performing appropriately.
 Figure 8: For the null values database visualization (Source: Self-created in Google Colab)
Figure 8: For the null values database visualization (Source: Self-created in Google Colab)
After dropping the database again it checked again via the heatmap which has been shown in the above snip. As it displays that there were no null values present at this time.
Experiment and Evaluation
After successfully dropping off the database as well as checking it via the functionality of heatmap now the entire database is totally prepared for the analysis of the linear regression.
 Figure 9: Test Train Split (Source: Self created in Google Colab)
Figure 9: Test Train Split (Source: Self created in Google Colab)
In linear regression the train test split generally applies to simply estimate the machine learning algorithm performance. In addition, the above snip that has been attached simply displayed the test train split in linear regression. As well, the test train split can be applied for the regression problems or classification as well as also applied for some kind of “supervised learning algorithm”.
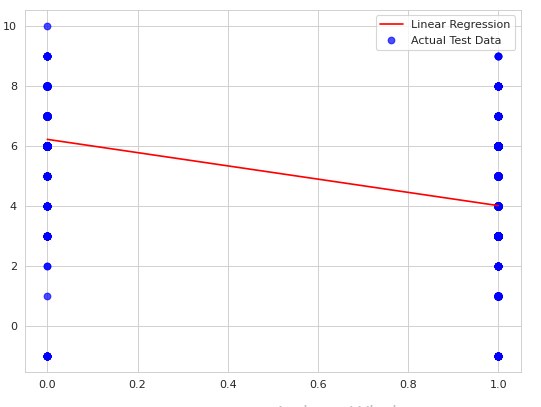 Figure 10: linear regression and actual test data graph (Source: Self-created in Google Colab)
Figure 10: linear regression and actual test data graph (Source: Self-created in Google Colab)
The machine learning technique linear regression is much simpler to recognize and describe and also can be formalized to ignore overfitting. As well, in the above snip it simply shows the respective graph of the linear regression and actual test data.
Implementation
The “exploratory data analysis” phases which analysts have in thought while working with exploratory data analysis incorporate vast amounts of knowledge about the domains of problem, asking appropriate questions that are connected with the data analysis purpose and set clean objectives which are lined up in addition to the expected outcomes. In this assignment the exploratory data analysis is used just because of its abilities.
The exploratory data analysis generally includes not only the statistics but also the visualization to simply measure and calculate as well as specify the trends in the analysis of the data. More than that, exploratory data analysis has several kinds of advantages such as with the help of exploratory data analysis the user can simply improve the recognition of variables by taking out the mean, medium, averages as well as the maximum values and many more. The exploratory data analysis simply help to find out the outliers, errors as well as also the values that are missing in the data.
Also it helps to specify the data patterns by visualizing the entire database in graphs like scatter plots, box plots as well as histograms. On the other hand linear regression is also also used in this assignment just because it is the reliable technique of specifying the exact variables that have effect on the “topic of interest”. In addition, the procedure of working with the regression permits the user to determine confidently which parameters matter most and what the parameters that can be avoided as well as how it simply encourages each other.
Conclusion
This assignment basically comes up with the data analysis. In addition, in this assignment it has been discussed the machine learning methods such as the linear regression and exploratory data analysis. Lit also described the brief benefits of these two machine learning methods. As well, it also performed the detailed analysis of the data with snips of each and every step such as data cleaning, data checking, null values checking and many more.
Reference list
Journals
[3]T. Pranckevičius and V. Marcinkevičius, “Comparison of Naive Bayes, Random Forest, Decision Tree, Support Vector Machines, and Logistic Regression Classifiers for Text Reviews Classification”, Baltic Journal of Modern Computing, vol. 5, no. 2, 2018. Available: 10.22364/bjmc.2017.5.2.05.
[4]K. Shah, H. Patel, D. Sanghvi and M. Shah, “A Comparative Analysis of Logistic Regression, Random Forest and KNN Models for the Text Classification”, Augmented Human Research, vol. 5, no. 1, 2020. Available: 10.1007/s41133-020-00032-0.
[5]M. Chen, K. Ubul, X. Xu, A. Aysa and M. Muhammat, “Connecting Text Classification with Image Classification: A New Preprocessing Method for Implicit Sentiment Text Classification”, Sensors, vol. 22, no. 5, p. 1899, 2022. Available: 10.3390/s22051899.
[6]”CHALLENGES IN TEXT CLASSIFICATION USING MACHINE LEARNING TECHNIQUES”, International Journal of Recent Trends in Engineering and Research, vol. 4, no. 2, pp. 81-83, 2018. Available: 10.23883/ijrter.2018.4068.k3orb.
[7]K. EL bendadi, Y. Lakhdar and E. Sbai, “An Improved Kernel Credal Classification Algorithm Based on Regularized Mahalanobis Distance: Application to Microarray Data Analysis”, Computational Intelligence and Neuroscience, vol. 2018, pp. 1-9, 2018. Available: 10.1155/2018/7525786.
[8]Q. She, K. Chen, Y. Ma, T. Nguyen and Y. Zhang, “Sparse Representation-Based Extreme Learning Machine for Motor Imagery EEG Classification”, Computational Intelligence and Neuroscience, vol. 2018, pp. 1-9, 2018. Available: 10.1155/2018/9593682.
[9]X. Liao, X. Liao, W. Zhu, L. Fang and X. Chen, “An efficient classification algorithm for NGS data based on text similarity”, Genetics Research, vol. 100, 2018. Available: 10.1017/s0016672318000058.
[10]S. Larabi Marie-Sainte and N. Alalyani, “Firefly Algorithm based Feature Selection for Arabic Text Classification”, Journal of King Saud University – Computer and Information Sciences, vol. 32, no. 3, pp. 320-328, 2020. Available: 10.1016/j.jksuci.2018.06.004.
[11]S. Bahassine, A. Madani, M. Al-Sarem and M. Kissi, “Feature selection using an improved Chi-square for Arabic text classification”, Journal of King Saud University – Computer and Information Sciences, vol. 32, no. 2, pp. 225-231, 2020. Available: 10.1016/j.jksuci.2018.05.010.
[12]M. Tomer and M. Kumar, “Multi-document extractive text summarization based on firefly algorithm”, Journal of King Saud University – Computer and Information Sciences, 2021. Available: 10.1016/j.jksuci.2021.04.004.
Know more about UniqueSubmission’s other writing services:
