COMP1702 Big Data Assignment Sample
Module Code And Title : COMP1702 Big Data Assignment Sample
PART 1
TASK A.1
Big data is a collection of data from a wide range of origins that’s still often defined in terms of five components: quantity, worth, range, pace, and truthfulness.

Volume-The quantity and volume of big information that businesses maintain and study is called quantity.
Value-The value of big data stems via insights discoveries and pattern identification that leads to the more productive operations, stronger customer relationships, as well as other clear and tangible economic effects.
Variety-Unsupervised learning, tractor trailer data, including original data were only ever a few illustrations of diverse data forms possible.
Speed is defined as the rate upon which money and financial, save, and process information – for example, the volume of posts on social media or queries processed in a certain workday, minute, or other timeframe.
Accuracy refers to the “true” or integrity of data and data assets, which is commonly used to establish executive credibility.
Variety is an extra quality that could be regarded:
Variability: the shifting pattern of data that companies seek to capture, handle, and monitor – for example,, variations there in meanings of key phrases in sentiment or computational linguistics. Unsupervised learning, tractor trailer data, including original data were only ever a few illustrations of diverse data forms possible.
Velocity- Speed is defined as the rate upon which money and financial, save, and process information – for example, the volume of posts on social media or queries processed in a certain workday, minute, or other timeframe.
Accuracy- Accuracy refers to the “true” or integrity of data and data assets, which is commonly used to establish executive credibility. Variety is an extra quality that could be regarded:
Variability: the shifting pattern of data that companies seek to capture, handle, and monitor – for example, variations there in meanings of key phrases in sentiment or computational linguistics.
TASK 2.1
RDBMS and Hadoop difference inside that RDBMS saves unstructured material, whereas Hadoop collects formatted, tractor trailer, and unstructured. The database management system (RDBMS) is indeed a database server based mostly on basic architecture.
HADOOP in personal qualification
Hadoop is capable of recording and assessing emotion information. Emotion data are unregulated factoids like opinions, opinions, and emotions that are commonly found on social platforms, blogs, customer care encounters, and web evaluations, among some other areas. Corporations can analyze emotion data to better understand whether company users and core audience feel about their products and services.
It aids enterprises in assessing their competitors and brand image. This attitude analytics alerts enterprises to modifications in product, production, and sales that would need to be made. Hadoop allows doing good semantic analysis on large amounts of material. Hadoop handles three aspects of Big Data rapidity, size, and heterogeneity with its pieces.
Using the Glitch mob / Sqoop apis, Hadoop could easily collect real – time data from online communities and database systems. Large amounts of data may be stored quickly with Hadoop Hadoop and Hive. With MapReduce or Hadoop, Hadoop supports combined deep learning and linguistic sentiment of text. Sentiment in the Hadoop system achieves highest sensitivity despite operating fast and at a fair price.
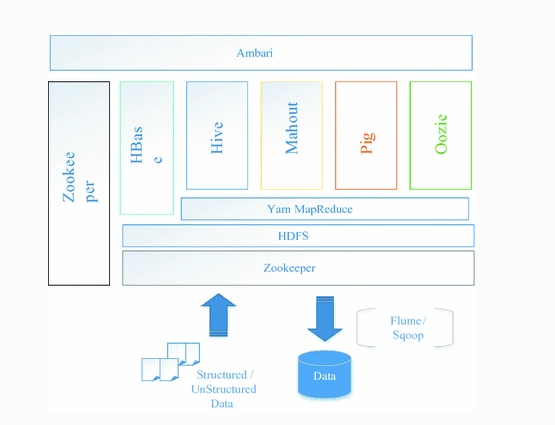 Figure 1: Hadoop Usage (www.mdpi.net)
Figure 1: Hadoop Usage (www.mdpi.net)
Hadoop’s file storage skills are offered via Hadoop and Hive. HDFS (Hadoop Distributed File System) is indeed a shared file way to store data from various types. It leads to higher access to executable files. Data like syslog or directories might well be collected and put in HDFS employing MapReduce software. Hadoop’s MapReduce function at its core. That’s a java-based technology which enables it to create applications which process high amounts of information in parallel. A MapReduce job divides the data coming set in individual parts which are analyzed in sequence by search processes.
PART B
Map Reducing Algorithm
Map and Reduce are two key jobs in the Hadoop mapreduce. Mapper Classes was doing the mappings operation. Reducer Class has been used to complete the process of reduction the data is quantized, transformed, and categorized by the Mapper subclass. The Reducer class uses the data of the Mapper method as feed and search for and cuts suitable pairs(Goldkind et al. 2018).
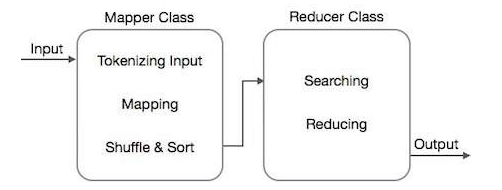 Figure 2: Map reduce Algorithm (www.khuiv.net)
Figure 2: Map reduce Algorithm (www.khuiv.net)
It uses a number of applied mathematics to dissolve a work into small chunks and redistribute them across various systems. The Map Reduce engine, in technical language, aids in the deployment of Map reduce jobs over a network of machines.
The following are the examples of computational models.
Sorting
Indexing
TF-IDF
Searching
Task B.2
One of the most common methods for evaluating topology differences between two trees is indeed the Richardson (RF) separation [10]. Removing an aspect (or bipartition) from such a branch T with taxa breaks trunk T into two sets, S1 and S2. Every one of the n taxa is classed as S1 or S2. Considering forest T’s bipartition B.
This bipartition might well be expressed as S1|S2, with S I becoming the identities of the organisms in that set. In comparing the sets of bipartitions of two, the RF distance derives the logical distance across them. Let’s ’s define the set of bipartitions that could be located in tree T. T I and T j are divided by the equivalent RF location.
Algorithm 1:
Class Mapper
2: method Map (docid a, doc d)
3: for all term t ∈ doc d do
4: Emit (term t, count 1)
1: class Reducer
2: method Reduce(term t, counts [c1, c2, . . .])
3: sum ← 0
4: for all count c ∈ counts [c1, c2, . . .] do
5: sum ← sum + c
6: Emit(term t, count sum)
Algorithm 2 mapper word count
class Mapper
2: method Map (docid a, doc d)
3: H ← new AssociativeArray
4: for all term t ∈ doc d do
5: H{t} ← H{t} + 1 . Tally counts for entire document
6: for all term t ∈ H do
7: Emit(term t, count H{t})
In different settings, it outperforms. LATE techniques use three factors: I choose work to be speculative, ii) identifying faster units to perform on, but iii) restricting speculating processes to reduce churning. It operates only suitable slow activities, although it is unable to assess the leftover time to do things properly or locate the very slow activities. Moreover, a SAMR (Soul MapReduce) routing algorithm is introduced, which can dynamically detect stagnant jobs by hyperparameters based on previous stored data on each cluster. As compared to FIFO, SAMR decreases runtime by 25% and by 14% when compared to Delay(Mikalef et al. 2020).
Part C
Big data project Analysis
For the purpose of big data projects Data Lake must be the better choice. A data lake is indeed a consolidated storing, storage, and camera system encompassing a large amount of processed, tabular, and unstructured data. It can retain and interpret information through its native format, with really no size limits.
A data lake is a configurable and safeguard app that lets organizations to: imbibe any statistics from every mechanism anywhere at flow rate it’s from being on, cloud, or boundary computational capabilities; purchase any what kind or amounts of data in replete fidelity; workflow info or batch mode; as well as interpret information utilizing SQL, SciPy, R, or really any dialect, fourth data, or data analysis approval process.
Data lake is better as the phrase “actual data ” information which has not been processed for a clear objective. The architecture of unprocessed vs. data input is by far the most major difference between data storage and data stores. Crude, unfiltered files are saved in data lakes, while highly processed information is held in data warehouses.
The data lake is appropriate for users who conduct in-depth investigation. Computer scientists, for instance, demand various statistical methods which include predictive analysis and data methods. Even though it is well structured, easy to use, and understandable, the database server is ideal for experience involving. Data warehouses typically contain quantitative metrics as well as the attributes that describe them, and also data extracted through transaction processing systems.
Web service logs, sensors, social media network activity, language, and images are all types of non data sources. Potential apps for these data kinds begin to evolve, but ingesting and keeping them could be expensive and moment. These – anti data types are welcomed by the data lake approach. Humans retain all data in a data lake, regardless of source or structure. Humans retain that in its natural form and therefore only modify it when we really need it.
This process is known as “Structure on Download,” as opposed to the big warehouse’s “Conceptual framework on Write” methodology. There are many things for what one must choose data lake which are,
- All data is retained by data lake
- All kind of data types are supported by data types
- All users are supported by the Data lakes.
- Adapting of data lake is very easy for changing
- Faster inside is provided by data lake (Rezaee et al.2018).
Task C.2
Data garden can be a good choice for the purpose of building plants. Data Garden is indeed a new sort of infrastructure that encourages, environments, and technologies to collaborate collaboratively. Device that is capable of turning digital information, including such texts, Patterns and textures, and Audio files, into a biologic format, DNA, using ACGT but instead of ascii. The DNA of a flower is translated instantaneously with trying to cut genotyping technology and projected in air within the artwork, revealing concealed messages.
The Data Gardens allows tourists to visit a new materiality to data, and to experience a future wherein storage capacity is truly sustainable, and exists as an open public asset that is shared within societies, by working alongside natural to reduce the problem of ‘data overheating.’ This process commences whenever a liquid is delivered to a single – cell rna sequencing, that scans the hereditary data to reveal hidden message, melodies, and visuals to also be enjoyed in spacetime. The setup features a real information feed that displays how so much Carbon dioxide it really has gathered.
The initiative depicts a world in which organisms, environments, and technology collaborate to develop design. As an online project created for SXSW, it introduces the public to advanced technology and also vital issues including such Data Heating (a word coined by GYOC to describe the connection among greenhouse gases and storage systems), genetic modification, and synthetic biology. Visualizations and a set of posters accompany the exhibit to highlight such themes.
The artwork includes tobacco and Plants coded with selected data related to Information Heating utilizing in vivo Genomic high – performance systems, created by Build One’s Own Clouds and Professor Jeff Said is, chief research at MISL, College of Seattle.
The decoding process used ATCG rather than binary to convert numbers online like Jpeg format and Audio files into DNA. Samplings from the crops are taken to produce droplets of aqueous Chromatin that are translated using a nanopore sequence to extract the data. The decrypts implemented are then fed into Touch Designer via Python, revealing the information stored in the plant(Wilkin et al.2020).
Task C.3
Map reduce is the best way for a new database, Map and Reduce are two important jobs inside the Mapreduce framework.
The Map task translates one set of data into a new set of data wherein individual components are split down into itemsets (key-value pairs).The Reduction task takes the Map’s output as just an argument and compresses the tuples (crucial pairs) into a shorter set. In the intervention stage, there have such a Record Readers that parses each record in an input data and passes the data to the mapping as two keys. Map is indeed a consumer method that takes a summary of important combinations and analyzes each to produce 0 or maybe more key-value pairs. Inter Keys the intermediary values are the key-value pairs produced by the mapping.
A coupler is a type of local Dampener that combines related data from the map phase into distinct sets. It takes the intermediary values from the map and aggregates the values in a small scope with one mapping that uses a user-defined code. It’s not part of the main Map reduce. Choosing MapReduce is the best way to handle big data.
By separating terabytes into smaller bits then executing these in simultaneously on Hadoop cheap machines, MapReduce improves simultaneous management sets. Ultimately, it aggregates all of data from many locations and delivers an aggregated view to the app. The Task tracker transforms a data collection it in to a new data set wherein individual parts are divided into packets (key-value pairs).
The Reduction making constant the Map’s result as an in and compresses the tuples (crucial pairs) into a small group. A most notable aspect of MapReduce is its extreme flexibility, that might extend to thousands of servers. Biodiversity in tandem – Perhaps one MapReduce’s main great benefits is it is parallel in design. Collaborating with the both unstructured and structured data at the same time is ideal.
One of MapReduce’s major great benefits is it is parallel in structure. Interacting with the both organized and unstructured information at the same time is great. In compared to those other Hadoop ecosystem, Dremel doesn’t really require a lot of RAM. It really can operate with little to no Main memory and yet still provide results quickly.
Task C.4
 Figure 3: Algorithm Host design (www.firebase.net)
Figure 3: Algorithm Host design (www.firebase.net)
Cloud hosting strategy helps in several ways such as helping in security and also in scalability. Whenever you stretch diagonally (out or in), it can add additional capabilities to the systems, including processors, to divide the load across multiple machines, which boosts efficiency and energy storage. Microsoft Azure, usually referred to as cloud computing, is a number of security mechanisms aimed at preserving internet infrastructure, services, and communications.
User or device identity, data & capacity user access, and data online privacy are all provided by all these methods. Cloud computing makes it extremely simple to swiftly deploy resources to meet a webpage or application’s evolving needs. From resources in the set of servers, one can add or remove assets like memory, internet, and Memory. Second csps host cloud service. To use another cloud, a company doesn’t have to assemble it because the service cares for just about everything. Clients use many internet browsers to utilize a supplier’s online services. Permissions, access control, and verification are all major security elements for cloud systems.
And they’re normally limited to a specific community or customer and dependent on that team’s or participant’s gate, cloud systems are generally better safe than cloud systems. Since they are only accessed through one entity, the isolated structure of these platforms helps them to stay protected from outside assaults. Nonetheless, some threats, like social engineering and data thefts, pose great vulnerabilities. It could also be difficult to cover such clouds.
Reference List
Journals
Wilkin, C., Ferreira, A., Rotaru, K. and Gaerlan, L.R., 2020. Big data prioritization in SCM decision-making: Its role and performance implications. International Journal of Accounting Information Systems, 38, p.100470.
Rezaee, Z. and Wang, J., 2018. Relevance of big data to forensic accounting practice and education. Managerial Auditing Journal.
AlNuaimi, N., Masud, M.M., Serhani, M.A. and Zaki, N., 2020. Streaming feature selection algorithms for big data: A survey. Applied Computing and Informatics.
Goldkind, L., Thinyane, M. and Choi, M., 2018. Small data, big justice: The intersection of data science, social good, and social services. Journal of Technology in Human Services, 36(4), pp.175-178.
Lele, A., 2019. Big data. In Disruptive Technologies for the Militaries and Security (pp. 155-165). Springer, Singapore.
Barua, H.B. and Mondal, K.C., 2021. Cloud big data mining and analytics: Bringing greenness and acceleration in the cloud. arXiv preprint arXiv:2104.05765.
Mikalef, P., Krogstie, J., Pappas, I.O. and Pavlou, P., 2020. Exploring the relationship between big data analytics capability and competitive performance: The mediating roles of dynamic and operational capabilities. Information & Management, 57(2), p.103169.
Mikalef, P., Krogstie, J., Pappas, I.O. and Pavlou, P., 2020. Exploring the relationship between big data analytics capability and competitive performance: The mediating roles of dynamic and operational capabilities. Information & Management, 57(2), p.103169.
Mikalef, P., Krogstie, J., Pappas, I.O. and Pavlou, P., 2020. Exploring the relationship between big data analytics capability and competitive performance: The mediating roles of dynamic and operational capabilities. Information & Management, 57(2), p.103169.
Know more about UniqueSubmission’s other writing services:

Your point of view caught my eye and was very interesting. Thanks. I have a question for you.