COMP1814 Statistical Techniques with R Assignment Sample
Module Code And Title : COMP1814 Statistical Techniques with R Assignment Sample
Introduction
R is nothing but a dependable statistical analytics software program. It includes a comprehensive statistical library with support for T-tests, logistic regression, time information processing and linear regression. Statistical Research using R studio is among the best techniques employed by statisticians, computer engineers, especially data analysts when evaluating statistical datasets. R language is a very famous open-source computing language which has a large number of built-in plus outside statistical analysis tools. The R programming language provides simple statistical computations for exploration input as well as sophisticated statistics for prediction data processing. Statistical analysis using R language as a critical component of detecting data structures which is based on the statistical principles as well as business limitations. Because of the ease of use of sophisticated modules plus the purity of the R language. For that in the statistical analysis, the R programming language is chosen.
R tools and Statistical Methods
ggplot2 is a well-known R programme for producing visuals.

dplyr: A prominent R tool for handling information efficiently.
tidyr: A tool for cleaning up sets of information in R language.
readr is a R tool that allows the users to read in data.
qqplot: In complement to the ordinary distributions, the qqPlot permits the operator to define a variety of other distributions as well as, alternatively, calculate the distribution variables of the suited distribution.
Scatterplot: A scatter plot (also known as a scatter diagram or scatter-chart) employs points to indicate the values of two numerical factors.
Boxplot: A box plot seems to be a type of chart which shows how the variables in the dataset are distributed.
Histogram: A histogram representation is a graphical representation of the distributions of an univariate information gathering.
geomplot: The structure of the ggplot2 layer is defined by the geom plot.
Importance of the Statistical analysis with the help of R
- R is a dependable statistical research software language.
- It includes a comprehensive statistical library with support for T-tests, time-series data, linear regression and logistic regression processing.
- R has excellent data visualization tools that include charts as well as diagrams using graphical programmes such as ggplot2.
- This is a scripting language that assists statisticians including data analysts in the development and testing of specific statistical algorithms for efficient information processing.
- The R language code for the statistical analysis is straightforward to read as well as share with other stack users in the company and collaborators.
- Considering R language is a successful plus well languages, this has a number of program reusability and libraries accessible to help you get begun with the statistical analysis of such an input sequence.
- The R programming language contains a number of built-in databases for learning including developing a working prototype before employing actual company information for statistical research.
Task1
- The required code for Mice
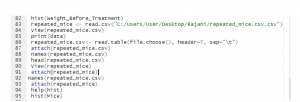 Figure 1: The required code for the histogram (Source: Self-Created in RStudio)
Figure 1: The required code for the histogram (Source: Self-Created in RStudio)
- The Histogram of weight Before Treatment for Rats
 Figure 2: The required code for the histogram (Source: Self-Created in RStudio)
Figure 2: The required code for the histogram (Source: Self-Created in RStudio)
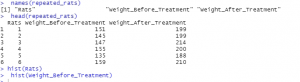 Figure 3: Dataset display (Source: Self-Created in RStudio)
Figure 3: Dataset display (Source: Self-Created in RStudio)
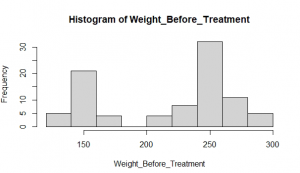 Figure 4: The Histogram plot of rat’s weight for before treatment (Source: Self-Created in RStudio)
Figure 4: The Histogram plot of rat’s weight for before treatment (Source: Self-Created in RStudio)
The Histogram of weight After Treatment for Rats
 Figure 5: The required code for the histogram (Source: Self-Created in RStudio)
Figure 5: The required code for the histogram (Source: Self-Created in RStudio)
 Figure 6: The obtained result (Source: Self-Created in RStudio)
Figure 6: The obtained result (Source: Self-Created in RStudio)
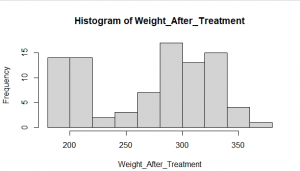 Figure 7: The Histogram plot of rat’s weight for after treatment (Source: Self-Created in RStudio)
Figure 7: The Histogram plot of rat’s weight for after treatment (Source: Self-Created in RStudio)
- Scatter Plot
Code for rats weight before treatment:
plot(x = Rats,y = Weight_Before_Treatment,
xlab = “Rats”,
ylab = “Weight_Before_Treatment”,
main = “Weight of the rats before treatment”
)
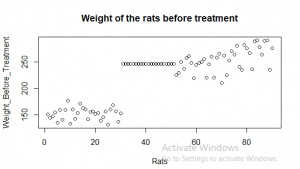 Figure 8: The required Scatter plot (Source: Self-Created in RStudio)
Figure 8: The required Scatter plot (Source: Self-Created in RStudio)
Code for rats weight after treatment:
plot(x = Rats,y = Weight_After_Treatment,
xlab = “Rats”,
ylab = “Weight_After_Treatment”,
main = “Weight of the rats after treatment”
)
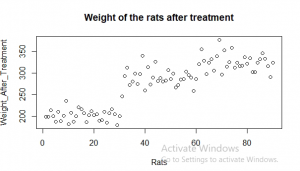 Figure 9: The required Scatter plot (Source: Self-Created in RStudio)
Figure 9: The required Scatter plot (Source: Self-Created in RStudio)
- The boxplot operation
Boxplots might appear crude in contrast to the histogram or even to the density graph, although they have some benefits like boxplot taking less space that is beneficial for comparing distributions over several categories or datasets.
First, for rats weight before treatment
repeated_rats<- read.table (file.choose (), header=T, sep=”\t”)
attach(repeated_rats)
names(repeated_rats)
head(repeated_rats)
help(hist)
?hist
hist(Rats)
hist(Weight_Before_Treatment)
hist(Weight_After_Treatment)
boxplot(Weight_After_Treatment)
boxplot(Weight_Before_Treatment)
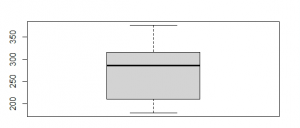 Figure 10: The Box plot of rat’s weight for before treatment (Source: Self-Created in RStudio)
Figure 10: The Box plot of rat’s weight for before treatment (Source: Self-Created in RStudio)
Second, for rats’ weight after treatment
repeated_rats<- read.table (file.choose (), header=T, sep=”\t”)
attach(repeated_rats)
names(repeated_rats)
head(repeated_rats)
help(hist)
?hist
hist(Rats)
hist(Weight_Before_Treatment)
hist(Weight_After_Treatment)
boxplot(Weight_After_Treatment)
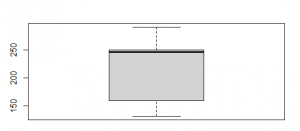 Figure 11: The Box plot of rat’s weight for after treatment (Source: Self-Created in RStudio)
Figure 11: The Box plot of rat’s weight for after treatment (Source: Self-Created in RStudio)
Geom_line plot
Code for rats weight before treatment:
plot(v,type = “o”, col = “red”, xlab = “Rats”, ylab = “Weight_Before_Treatment”, main = “Rats vs Weight before treatment”)
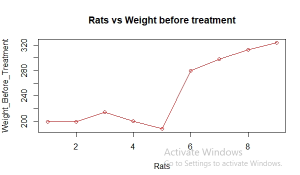 Figure 12: The required Geom_v plot (Source: Self-Created in RStudio)
Figure 12: The required Geom_v plot (Source: Self-Created in RStudio)
Code for rats weight after treatment:
plot(v,type = “o”, col = “blue”, xlab = “Rats”, ylab = “Weight_After_Treatment”, main = “Rats vs Weight After treatment”)
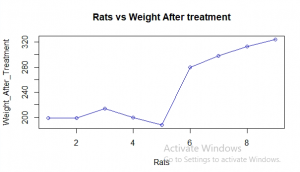 Figure 13: The required Geom_v plot (Source: Self-Created in RStudio)
Figure 13: The required Geom_v plot (Source: Self-Created in RStudio)
Task 2
- qq plots code for mice weight before treatment
Mice
install.packages(“qqplot”)
library(qqplot)
qqnorm(Mice$Weight_Before_Treatment)
qqline(Mice$Weight_Before_Treatment, col=”red”)
qq plots code for mice weight after treatment
Mice
install.packages(“qqplot”)
library(qqplot)
qqnorm(Mice$Weight_After_Treatment)
qqline(Mice$Weight_After_Treatment, col=”red”)
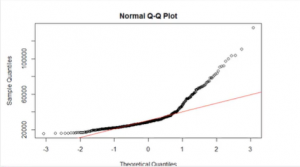 Figure 14: The qq plot representation (Source: Self-Created in RStudio)
Figure 14: The qq plot representation (Source: Self-Created in RStudio)
Serpio-Wilk test for Mice weight before treatment
Mice
install.packages(“Serpio-Wilk-test”)
Serpio.Wilk.test((Mice$Weight_Before_Treatment)
Serpio-Wilk test for Mice weight after treatment
Mice
install.packages(“Serpio-Wilk-test”)
Serpio.Wilk.test((Mice$Weight_After_Treatment)
- qq plots code for rats weight before treatment
Rats
install.packages(“qqplot”)
library(qqplot)
qqnorm(Rats$Weight_Before_Treatment)
qqline(Rats$Weight_Before_Treatment, col=”red”)
qq plots code for rats weight after treatment
Rats
install.packages(“qqplot”)
library(qqplot)
qqnorm(Rats$Weight_After_Treatment)
qqline(Rats$Weight_After_Treatment, col=”red”)
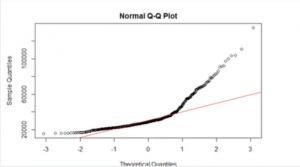 Figure 15: The qq plot representation (Source: Self-Created in RStudio)
Figure 15: The qq plot representation (Source: Self-Created in RStudio)
Serpio-Wilk test for Rats weight before treatment
Rats
install.packages(“Serpio-Wilk-test”)
Serpio.Wilk.test((Rats$Weight_Before_Treatment)
Serpio-Wilk test for Rats weight after treatment
Rats
install.packages(“Serpio-Wilk-test”)
Serpio.Wilk.test((Rats$Weight_After_Treatment)
- From the qq plot diagram it is clear that this dataset for both the cases means that 200 mice’s weight and 200 rat’s weight before as well as after treatments are not normally distributed. In case of log transformation still the values are not correctly normally distributed. Two datasets are compared with the help of boxplot and the obtained result shows that the weight of the rats and mices are increased after treatment.
Task 3
- T-Test
T-tests in the R languages are among the greatest often used statistical tests. As a result, developers utilise this to assess if the means of different categories are identical. The test assumes that both categories are drawn from the normal distribution having equal eccentricities.
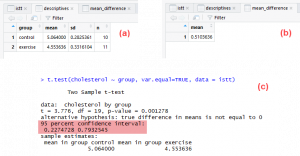 Figure 16: T-Test (Source: https://statistics.laerd.net)
Figure 16: T-Test (Source: https://statistics.laerd.net)
- Degrees of freedom
In case of chi-square analysis, the equation for computing ‘degrees of freedom’ for a particular table is (r-1) (c-1), whereby r denotes the number of rows while c is the number of columns.
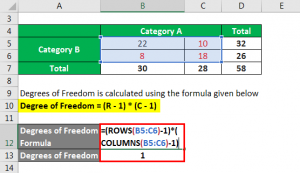 Figure 17: Degrees of freedom (Source: https://www.educba.net)
Figure 17: Degrees of freedom (Source: https://www.educba.net)
- P-value
P-values may be calculated in R utilising ‘cumulative distribution functions’ as well as the ‘inverse cumulative distribution functions’ of a specified sample distribution.
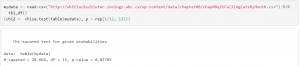 Figure 18: The code for P Value (Source: https://rpubs.net)
Figure 18: The code for P Value (Source: https://rpubs.net)
- Confidence Interval
Confidence intervals (CI) represent inferential statistics which aid in drawing conclusions regarding a community from a subset. A genuine demographic mean is expected to be represented by a spectrum of values known as a confidence interval depending on the degree of confidence (Flores, et al. 2018.). The general guideline to observe is that the greater the ‘confidence level’, the broader the interval. Since CI is stated, it is critical to pay attention to the given confidence level.
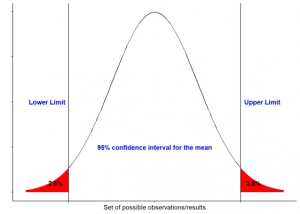 Figure 19: Confidence Interval (Source: https://www.r-bloggers.net)
Figure 19: Confidence Interval (Source: https://www.r-bloggers.net)
- Sample estimates
Sample statistics refer to sample properties including the sample means, sample variance, as well as sample percentage. Estimates are classified into two forms: point estimates plus interval estimates. Point estimate is a unique estimate which refers to the population’s proportion based on the magnitude of a sample statistics.
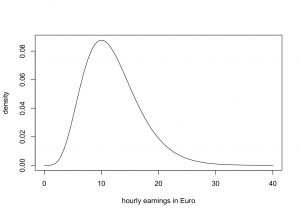 Figure 20: Sample Estimates (Source: https://www.econometrics-with-r.org)
Figure 20: Sample Estimates (Source: https://www.econometrics-with-r.org)
Task 4
Fitdist in R
Fitting distributions onto information is a typical activity in statistics which entails selecting a probabilistic model to represent the random value and also estimating parameter values for that particular distribution. This takes judgement as well as knowledge, and an iterative procedure of distribution selection, parameter estimate, including degree of fit evaluation (Gupta, et al. 2021). Maximum probability estimate is accessible in the R packages MASS through the fitdistr method; further parts of the matching procedure can be performed utilising other R methods. In this work, developers introduce fitdistrplus, in the R package that implements many techniques for fitting unitary parametric distributions. The primary goal in designing this module was to give R programmers with a collection of procedures targeted to assisting with this whole process.
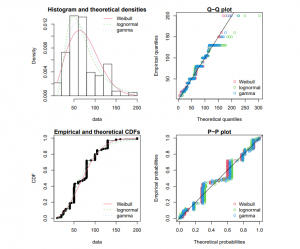 Figure 21: The output of different types of R tools (Source: https://cran.r-project.org)
Figure 21: The output of different types of R tools (Source: https://cran.r-project.org)
Conclusion
The complete project work is concluded here by the developers. This is a step of computer science initiatives that is integrated. Along with its inbuilt statistical calculation functionality with widespread community engagement, it distinguishes itself from rivals such as Python, SPSS, IBM SAS, Statistics, Microsoft Excel, Minitab, as well as MATLAB. With each version update, statistical modelling in R evolves. In this particular project several R tools are used and after programming the output also generated by the developers to understand the importance and effect of the statistical analysis with
Reference list
Journal
Gupta, B.C., 2021. Statistical Quality Control: Using MINITAB, R, JMP and Python. John Wiley & Sons.
Ciaburro, G., 2018. Regression Analysis with R: Design and develop statistical nodes to identify unique relationships within data at scale. Packt Publishing Ltd.
Flores, M., Fernández-Casal, R., Naya, S., Tarrío-Saavedra, J. and Bossano, R., 2018. ILS: An R package for statistical analysis in Interlaboratory Studies. Chemometrics and Intelligent Laboratory Systems, 181, pp.11-20.
Lüdecke, D., Ben-Shachar, M.S., Patil, I., Waggoner, P. and Makowski, D., 2021. performance: An R package for assessment, comparison and testing of statistical models. Journal of Open Source Software, 6(60).
Know more about UniqueSubmission’s other writing services:

Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.