Statistical Analysis and Dashboard Creation Assignment Sample
1.0 Introduction.
This research paper consists of dataset of ten distinct countries which are collected through the help of “World Development Indicators” i.e. WDI, which is considered as a primary world bank which helps in attaining all the data’s that are being required in executing the analysis of the tests. The data are being collected for ten years in order to complete the given task so as to get the desired results. The tests which are to be performed into this research paper are from the results which have been obtained from the SAS analytical steps, comprehensive descriptive statistical analysis which largely consists of mean, median, mode, skewness, standard deviation and kurtosis from the attained datasets, correlation analysis from the attained indicators in order to define the objective, regression analysis test which widely explains the regression technique which is being used in executing this test is better from the other tests which are being performed into this research paper and comparative analysis of the hypotheses is widely explained into the research paper which also widely discussed about the two types of hypothesis which are being related to the objective in order to perform the desired tests. This research paper also discusses the steps which are being used for preparing the data’s, outlier detection, data privacy protection and dealing with the missing data. SAS programming is being used for obtaining the desired statistical part of the analysis. Here in this research paper Power BI has been used in order to complete the analysis part which is being used in the development of the dashboard.
2.0 Background Research.
The art which is being used in the designing of the interactive dashboards generally consists of overwhelming data which helps in constant flow of the information which helps the users as well as the peoples in succeeding into their jobs. Therefore, dashboards help in serving the dull and opaque data’s into beautiful insights which resonate with most of the resonate users (Tsuchida et al. 2021). These are the key essential needs which are very much needed by the businessmen to transform their business. The dashboards mainly stand on four pillars i.e.
- Value which critically states that it must be useful.
- Usability which critically states that it must be easy to use.
- Adaptability which critically states that it must be easy to get started.
- Desirability which critically states that it must be exciting to use.
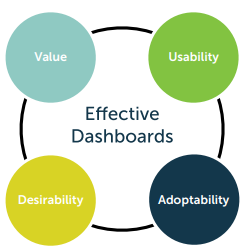
Figure 1: Four pillars of dashboard.

Yet another crucial element which is being used into the effective dashboards is comprises of carefully selection of useful as well as actionable information as too little information limits the action ability of the data which are cumbersome and are very hard to view the datasets. There are trends around the globe which use different kinds of datasets which are as follows
- The emergence of flat UI: These flat “user interfaces” which are being abbreviated as UI which has become a successful creation of the UI which generally offers straightforward minimalistic approach into the design (Rouhani et al. 2018). It widely uses two dimensional illustrations which significantly minimizes the shadows and gradient textures and three dimensional treatments which aesthetically helps in giving the pleasures to the users in order to process their data’s and their content quickly without any distraction.
- Enhancing mobility: Recent study suggests that the users which use BI widely into their databases from a mobile device helps them in attaining all the necessary data which are being required to change the overall scenario of the business. This allows in accessing all the relevant data remotely which helps the users in making the required decisions fast, simple and agile.
- Wire framing: Wire framing is a tool which is being used into the design purpose of the dashboards which displayed the useful as well as crucial information’s which generally streams consciousness data into visualization, which majorly helps the users in building the framework which is widely used to manage the components of the dashboard. This helps in reducing the distractions which are being significantly identified into the dashboards thus making the design less iterative. Thus the nascent is becoming a new trend which is proven to be prevalent as the designers are not overlooking the step.
- Color Blocking: Color Blocking is a feature which is embedded into the dashboards which helps in creating the colorful graphs and necessary items which are being needed into the dashboard which enhances the overall look of the database.
- Least not on the surface: generally the users are not logical always, sometimes it might be looked into the deeper part for better understanding of the dataset. Therefore dashboards deliver the information’s into an actionable insights which are relevant and are widely accepted by the audiences as well as the users (Alcivar et al. 2019). It majorly uses three distinct steps which are being followed such as minimization of the use of logos, excluding huge wireframes which uses huge graphics and reduction of the charts and graphics which uses less 3D effects and which are often found difficult in reading all the texts.
- Gauging and non-gauging: In the past decade the gauges have been considered as eye candy. The expectation of this outline type was really direct. On the off chance that client could peruse measures in their vehicles and tell how much gas they have, how quick they’re driving, and where their oil levels are, then, at that point, it would make an interpretation of well into the dashboard. While a few clients actually incline toward this representation measures are infamous for occupying significant room and giving restricted data since it presents information on a solitary aspect (González-González et al. 2020). All it truly tells whether something is on track, above target or underneath target. Line diagrams show patterns over the long run, bar graphs are incredible for examinations, projectile outlines are really great for targets, and if the inclination for being extravagant emerges choose a mixed bag of a few sorts of mixes. It’s dependent upon you where you need to fall on this incredible measure banter.
- Classy Icons: Classy icons are being introduced into the dashboard which helps in attaining the attention of the users which are frequently embedded with the classy icons into the navigational panel.
- Being dynamic: There is always a balance between the emotion and functionality which generally amplifies with the dashboard functions which proves to be very powerful. Therefore a dynamic dashboard generally provides the potential users in attaining all the data’s which are being required to update their own database and their new content which are being periodically updated into their databases for attaining all the required information within time limit.
- Interactivity: The present dashboards are utilizing more extravagant substance encounters through intelligent components like video, light boxes, overlays, slicers, and so forth to advance client commitment with the substance and to assist them with inferring further bits of knowledge (Mohammed and Quddus 2019). Abilities like zooming, drill-down and separating are turning out to be more ordinary too. A few dashboards even use social feeds to elevate brand devotion and convey continuous activities. It also helps in deriving the common phenomenon which is being widely used in illustrating the design which is being executed into the dashboards.
- Location: Due to the emergence of “global positioning system” i.e. GPS technologies which are embedded into the database of the devices, which helps in significantly tracking of the users by the help of maps which are more intelligent (Amin et al. 2018). The questions which are being answered into this part are total miles travelled by the user and in which region of the country.
3.0 Exploration of Data Set.
The dataset which has been provided into the research paper has significantly undergone with the critical evaluation which majorly uses data cleaning techniques so as to attain the desired result. The data cleansing method can be described as a process which is being used to fix or to remove the duplicate, corrupted, incorrectly formatted data’s into desired data’s which provides the useful results from which different sections of the datasets can be easily understandable. However, there is no such way by which the process of data cleaning can be described fruitfully as the process completely depends on different datasets (Amin and Valverde 2017). The general process which is being used in cleaning of the data’s in this research paper widely consists of the following steps which successfully helped in attaining the desired results which helped to improve the overall framework of the database. The steps are as follows
- Elimination of irrelevant and duplicate observations: Here, in this part the eliminations of the data has been made in order to make useful analysis in order to make more efficient and to minimize the distractions.
- Fixing of the errors (structural): Structural errors generally occur when transferring of the data which misguides as well as misleads.
- Filtering of the outliers: These occur due to improper data entry which are successfully removed by the filters within the database which helps in making an efficient database.
- Handling of the missing data: Which is being done through the algorithms which do not accept missing values into the datasets by the help of three distinct options (Mora 2020). The first option majorly consists of observations, second step consists of inputting of the missing values and the third step helps in effectively navigating null values.
- Validation of the data: This is considered as one of the end step of the data cleaning process where the data’s which are being used into the databases are being validated so as to get the desired results into the dashboard.
4.0 Investigation of Data Workflows and Proposal for Design of Dashboard.
Data mapping is the process which is being used as the most common way of extracting information from one or various source records and matching them to their connected objective fields in the objective. Data mapping likewise unites information by removing, changing, and stacking it to an objective framework. The underlying advance of any information interaction, including ETL which is data mapping (Tichem 2018). Organizations can involve the planned information for creating applicable experiences to further develop business proficiency. Therefore data mapping is considered as a crucial factor which commonly leads to the success of the data process. Most of the organizations use data mapping in order to ensure all the data attains into the destination accurately.it is mainly used in the processes such as “data integration, data migration, data warehouse automation, data synchronization, data extraction and data management processes” which helps in attaining quality data which are to be analyzed. However, data mapping is being widely considered as one of the main keys to the data management which helps in the process where the data’s are not managed properly and are mainly out of the required destination. Hence, quality in data mapping is being highlighted in order to attain “data migrations, integrations, transformations and populating a data warehouse”.
- Data migration: It is the process of moving the data into one system to another, which does not change the overall data during the process of migration as well as it helps in retaining the data into that particular space which has been attained by the users. Thus this helps in supporting the migration process by implementing the mapping sources into the required destinations.
- Data Integration: it is the process which helps in regularly moving of the data from one system to another, where the process is being scheduled and is divided into sub quarters or in months which are usually triggered by the events. Here the data is being stored into one destination which helps in accessing the required data anytime. Unlike data migration this part also integrates match fields with respect to the destination fields.
- Data transformation: it is the process which majorly converts the data from source format to the destination format. Which critically includes cleansing of the data’s from the changes which have been made into the datasets.
- Data Warehousing: When bundling information to a survey or another company’s hotspot, this is primarily bundled with the information warehouse (Ghaffar 2020). When a question is being asked, it runs a report or conducts a survey which critically consists of information retrieved from the warehouse. The information in the warehouse is currently being moved, integrated or changed. The information plan ensures that the information entering the vault reaches its destination as expected.
- The steps which are being followed into the data mapping mainly follow six steps which are as follows (Mena and Isaias 2019). The first step consists of defining of the data which are to be moved into the tables that consists of tables, second step consists of mapping of the data where the source is being matched into destination fields, third step consists of transformation where the formula of the transformation are generally coded, fourth step consists of testing where the sample is being tested and thus major adjustments are being made according to the adjustments which are being made, fifth step consists of deployment which critically follows the above step and then data transformation is being scheduled and planned for integration purposes and the last step consists of update and maintenance where the ongoing data are being integrated and are being changed in accordance to the updates which are to be made into the data.
Visual paradigm is a dashboard software which mainly consists of a “highly configurable data visualization tool” which is useful for the users in observing as well as understanding their data easily. This also helps in visualizing the data into valuable insights (Amin and Valverde 2017). Which also helps in the creation of the dashboards and perform ad-hoc data analysis by using a few steps, which produces a wide range of charts and graphs which helps the users in fulfilling their business needs. The intuitive spreadsheet editor which is present within the dashboard helps in visualizing the overall data within a few minutes.
The data which are being used to perform the comprehensive descriptive statistical analysis test which majorly consists of mean, median, mode, standard deviation, skewness and kurtosis from the given data, correlation analysis test from the given indicators, correlation analysis and regression analysis tests are being performed by taking the data from the “World Development Indicators” i.e. WDI among 10 countries which strictly follows the indicators to make the test result fruitful and which is shown below
4.1 Comprehensive descriptive statistical analysis.
Comprehensive descriptive statistical analysis test is being done in order to show, describe as well as summarize the basic features which are generally found into a dataset which critically describes the data sample and its crucial measurements (Buvinic and Swanson 2020). Hence, it helps the users in understanding the data better. There are mainly three types of descriptive statistics which are being used globally by the users in order to execute their test results, which widely consists of
- Central tendency: which majorly covers the values of the averages.
- Distribution: which majorly deals with the frequency of the values.
- Variability: which depicts the spread of the values.
However, the measure of the central tendency which is being used for the estimation purposes uses three methods which consist of mean, mode and median. Here in this test 10 countries have been selected according to the indicators which are being available into the WDI, which helped in making a clear Comprehensive descriptive statistical analysis test.
4.2 Correlation Analysis test.
| 4 With Variables | Annual GDP growth, urbanization rate, sucide rate, life expectancy. |
| 4 Variables | GDP per capita, population growth, sex-ratio, meat consumption |
| Pearson Correlation Coefficients, N = 10 | ||||
| GDP per capita | Population growth | Sex-ratio | Meat consumption | |
| Annual GDP growth Annual GDP growth | 0.4438 | 0.12706 | -0.15419 | -0.16733 |
| Urbanization rate Urbanization rate | -0.53574 | -0.15908 | 0.42892 | 0.2104 |
| Suicide rate Suicide rate | 0.15435 | -0.59324 | -0.26829 | 0.28238 |
| Life expectancy Life expectancy | 0.14421 | 0.49561 | -0.26537 | -0.14797 |
This test has been performed by considering 4 Variables which consists of Annual GDP growth, urbanization rate, suicide rate, life expectancy with respect to 4 variables which are GDP per capita, population growth and sex-ratio and meat consumption among the data which has been taken from 10 countries (Kaufmann 2019). The results have been outputted into the above table. Which critically illustrates that the population growth has a major impact with respect to the annual GDP growth and meat consumption have also declined due to the annual GDP growth of the countries. There is also decline into the GDP per capita and population growth with respect to the urbanization rates. The population growth and sex ratio has been declined due to the suicide rates and sex ratio and meat consumption has also been declined with respect to the life expectancy.
4.2 One way ANOVA test.
| Class Level Information | ||
| Class | Levels | Values |
| Annual GDP | 10 | 2010 -1.974958 6.957010063 -3.685029387 1.6028500483 14.362441469 3.7069381504 4.4039325434 4.7888729694 |
| growth | 5.1523365 | |
| Number of Observations Read | 10 |
| Number of Observations Used | 10 |
Dependent Variable: GDP per capita
| Source | DF | Sum of Squares | Mean Square | F Value | Pr > F |
| Model | 9 | 4.775E+09 | 530518130 | . | . |
| Error | 0 | 0 | . | ||
| Corrected Total | 9 | 4.775E+09 |
| R-Square | Coeff Var | Root MSE | GDP per capita Mean |
| 1 | . | . | 28040.4 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
| Annual GDP growth | 9 | 4.775E+09 | 530518130 | . | . |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| Annual GDP growth | 9 | 4.775E+09 | 530518130 | . | . |
Figure 2: Distribution of GDP per capita
| Level of | GDP per capita | ||
| Annual GDP growth | N | Mean | Std Dev |
| 2010 | 1 | 57214 | . |
| -1.97496 | 1 | 13213 | . |
| 6.95701 | 1 | 9027 | . |
| -3.68503 | 1 | 21977 | . |
| 1.60285 | 1 | 70441 | . |
| 14.36244 | 1 | 16265 | . |
| 3.706938 | 1 | 15399 | . |
| 4.403933 | 1 | 52144 | . |
| 4.788873 | 1 | 4099 | . |
| 5.152336 | 1 | 20625 | . |
Least Squares Means Adjustment for Multiple Comparisons: Tukey-Kramer
| Annual GDP growth | GDP per capita LSMEAN | LSMEAN Number |
| 2010 | 57214 | 1 |
| -1.97496 | 13213 | 2 |
| 6.95701 | 9027 | 3 |
| -3.68503 | 21977 | 4 |
| 1.60285 | 70441 | 5 |
| 14.36244 | 16265 | 6 |
| 3.706938 | 15399 | 7 |
| 4.403933 | 52144 | 8 |
| 4.788873 | 4099 | 9 |
| 5.152336 | 20625 | 10 |
Figure 3: LS-Mean for annual GDP growth.
(Source: SAS)
4.3 One way frequency test.
| Country | ||||
| Cumulative Frequency | Cumulative | |||
| Country | Frequency | Percent | Percent | |
| Cameroon | 1 | 10 | 1 | 10 |
| Canada | 1 | 10 | 2 | 20 |
| Colombia | 1 | 10 | 3 | 30 |
| Dominican Republic | 1 | 10 | 4 | 40 |
| India | 1 | 10 | 5 | 50 |
| Montenegro | 1 | 10 | 6 | 60 |
| Paraguay | 1 | 10 | 7 | 70 |
| Peru | 1 | 10 | 8 | 80 |
| Taiwan | 1 | 10 | 9 | 90 |
| United Arab Emirates | 1 | 10 | 10 | 100 |
Figure 4: Cumulative distribution of the country.
(Source: SAS)
| Annual GDP growth | ||||
| Cumulative Frequency | Cumulative | |||
| Annual GDP growth | Frequency | Percent | Percent | |
| -3.68503 | 1 | 10 | 1 | 10 |
| -1.97496 | 1 | 10 | 2 | 20 |
| 1.60285 | 1 | 10 | 3 | 30 |
| 3.706938 | 1 | 10 | 4 | 40 |
| 4.403933 | 1 | 10 | 5 | 50 |
| 4.788873 | 1 | 10 | 6 | 60 |
| 5.152336 | 1 | 10 | 7 | 70 |
| 6.95701 | 1 | 10 | 8 | 80 |
| 14.36244 | 1 | 10 | 9 | 90 |
| 2010 | 1 | 10 | 10 | 100 |
Figure 5: Distribution of annual GDP growth.
(Source: SAS)
Figure 6: Cumulative distribution of annual GDP growth.
4.4 Summary of the statistics.
| Variable | Label | Mean | Std Dev | Minimum | Maximum | N |
| V | V | 198.23631 | 640.11236 | -11.952693 | 2020 | 10 |
| Sex-ratio | Sex-ratio | 0.975 | 0.0340751 | 0.94 | 1.06 | 10 |
| Urbanization rate | Urbanization rate | 68.01 | 20.172834 | 36.3 | 90.1 | 10 |
| Annual GDP growth | Annual GDP growth | 204.53144 | 634.39615 | -3.6850294 | 2010 | 10 |
| GDP per capita | GDP per capita | 28040.4 | 23032.98 | 4099 | 70441 | 10 |
| Fertility | Fertility | 5.46 | 0.464758 | 4.5 | 6.1 | 10 |
| Life expectancy | Life expectancy | 70.27 | 7.9562763 | 58.9 | 82.3 | 10 |
| Meat consumption | Meat consumption | 44.34 | 34.33622 | 5.6 | 108.1 | 10 |
| Median age | Median age | 33.86 | 8.8792142 | 19.7 | 47.1 | 10 |
| Population growth | Population growth | 1.553 | 0.9932891 | -0.6 | 2.86 | 10 |
| Suicide rate | Suicide rate | 9.84 | 4.2539394 | 4 | 19.5 | 10 |
| M | M | 204.04745 | 634.90157 | -0.0080698 | 2011 | 10 |
| N | N | 204.50009 | 635.10989 | -4.9744437 | 2012 | 10 |
| O | O | 204.36263 | 635.49678 | -3.5475965 | 2013 | 10 |
| P | P | 204.30107 | 635.86546 | 0.3 | 2014 | 10 |
| Q | Q | 204.04384 | 636.30697 | 0.9435716 | 2015 | 10 |
| R | R | 203.31043 | 636.91694 | -2.5800496 | 2016 | 10 |
| S | S | 203.38006 | 637.24218 | -0.1472129 | 2017 | 10 |
| T | T | 203.51398 | 637.54755 | -2.0036297 | 2018 | 10 |
| U | U | 204.01198 | 637.72299 | -0.6246443 | 2019 | 10 |
4.5 T-test.
Annual GDP growth
| Tests for Normality | ||||
| Test | Statistic | p Value | ||
| Shapiro-Wilk | W | 0.372774 | Pr < W | <0.0001 |
| Kolmogorov-Smirnov | D | 0.517821 | Pr > D | <0.0100 |
| Cramer-von Mises | W-Sq | 0.647259 | Pr > W-Sq | <0.0050 |
| Anderson-Darling | A-Sq | 3.153703 | Pr > A-Sq | <0.0050 |
| N | Mean | Std Dev | Std Err | Minimum | Maximum |
| 10 | 204.5 | 634.4 | 200.6 | -3.685 | 2010 |
| Mean | 95% CL Mean | Std Dev | 95% CL Std Dev | ||
| 204.5 | -249.3 | 658.4 | 634.4 | 436.4 | 1158.2 |
| DF | t Value | Pr > |t| |
| 9 | 1.02 | 0.3346 |
Figure 7: Distribution of annual GDP growth.
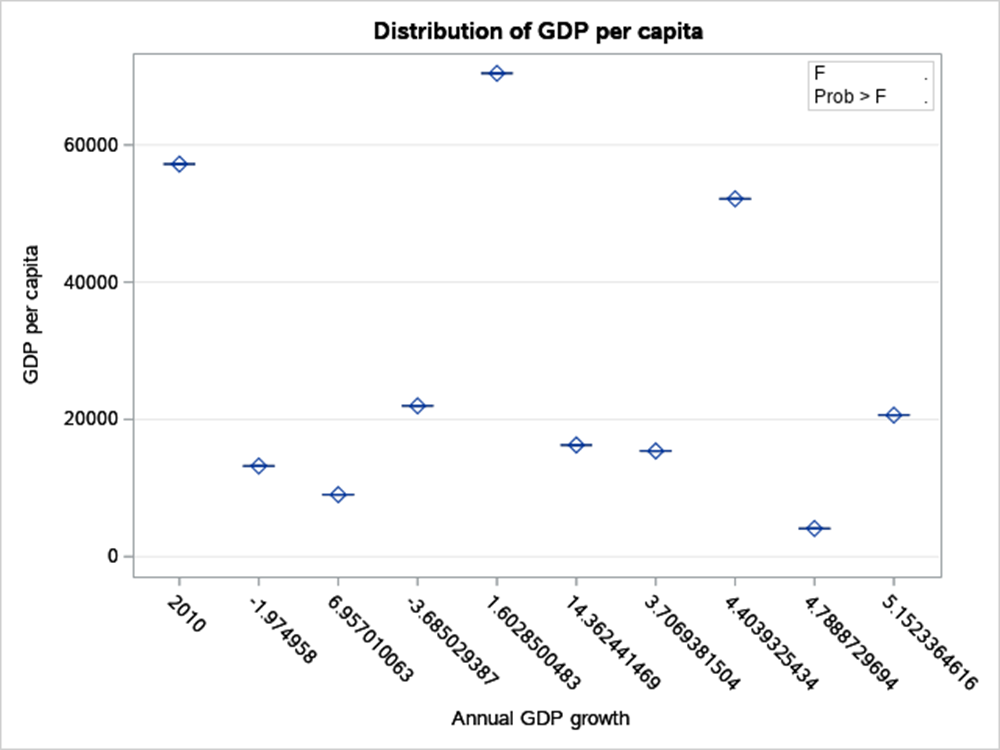
Figure 8: Q-Q Plot of annual GDP growth.
4.6 Hypothesis testing.
Hypothesis testing generally consists of three approaches critical value, p-value and confidence intervals (Donohoe and Costello 2020). But only two approaches are being used globally, that are critical value and p-value. This hypothesis test helps in governing the decisions which widely consists of accepting or rejecting a decision.
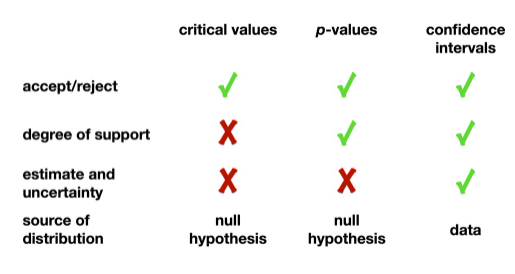
Figure 9: Functionality of the three hypothesis approaches.
The critical value approach test results are statistics and are more extreme to the critical value. In this manner the noticed test measurement is contrasted with the basic worth, some sort of cutoff esteem. Assuming that the test measurement is more limited than the basic worth, the invalid theory is dismissed (Costa and Aparício 2019). Assuming the test measurement isn’t generally as outrageous as the basic worth, the invalid speculation isn’t dismissed. The basic worth is registered depending on the given importance level and the sort of likelihood conveyance of the glorified model. The basic worth partitions the region under the likelihood conveyance bend in dismissal districts and in non-dismissal areas.
The p-value approach is considered as a numerical value which is being used to test the test statistics which are generally compared within the specific levels (significance) of the desired test. The p-value compares to the likelihood of noticing test information essentially as outrageous as the really acquired test measurement. Little p-values give proof against the invalid theory (Davis-Kean and Ellis 2019). The more modest the p-esteem, the more grounded is the proof against the invalid theory.
5.0 Discussion.
The approaches which have been taken while executing the tests from the data’s mainly consists of comprehensive descriptive statistical analysis test which have been performed by taken mean, median and mode into consideration, correlation analysis test have been performed by taking 4 variables i.e. Annual GDP growth, urbanization rate, suicide rate, life expectancy with respect to the other four valuable variables which majorly consists of GDP per capita, population growth, sex-ratio, meat consumption (Pitropakis et al. 2019). Which also depicts huge tables and figures which will help in better understanding of the results which have been obtained from the tests. One way ANOVA test has also been performed where the dependent variable taken is GDP per capita with respect to the annual GDP growth. One way frequency tests have also been performed by taking data from the 10 countries where the frequencies and their percentages have been illustrated into the table. A summary of the statistics have been shown into the table which majorly consists of the indicators which are being used while performing the test. Moreover, T-tests have also been performed which critically illustrate the tests with “Shapiro-Wilk, Kolmogorov-Smirnov, Cramer-von Mises, Anderson-Darling” with respect to the statistics and p-value. The workflow dashboard is considered as the initial screen which is being displayed when accessed to the dashboard module. It is also considered as the heart of the tap system, which provides an overall view of the active workflow. This workflow helps in monitoring of the permissions which are being granted and which also modifies the details of the workflow which generates reports. However, the workflow dashboard helps in updating the workflows which significantly helps in monitoring the work from one place to another hence the information which is being provided is always correct (Ellis et al. 2019). The navigation into the workflow dashboard can be made simpler which is mainly composed of the multi-page screen which are displayed as per the requirements which are made by the users. This helps in choosing the following requirements which are mainly done by the users such as search, sort, filter, toolbar utilities which are being used in order to configure the overall dashboard.
The dashboard which has been created by using the data’s from the WDI with respect to the 10 countries has been displayed below. Which critically illustrates the bar graph which shows median age difference of the particular 10 countries, list of countries which can be selected for filtering the results, rate of life expectancy of the particular countries, suicide rates and sex ratios of the particular countries, GDP per capita and urbanization rate, population growth, annual GDP growth of the country and filtering of the countries which can be made into the dashboard.
6.0 Conclusion.
This research paper mainly consists of creation of dashboard which has been created in Power-BI by using the data’s of the 10 countries which have been obtained from the “World Development Indicators” i.e. WDI which is also known as a primary world bank which consists of all the types of data’s which can be used in analyzing a particular country. The tests which are to be performed into this research paper are from the results which have been obtained from the SAS analytical steps, comprehensive descriptive statistical analysis which largely consists of mean, median, mode, skewness, standard deviation and kurtosis from the attained datasets, correlation analysis from the attained indicators in order to define the objective, regression analysis test which widely explains the regression technique which is being used in executing this test is better from the other tests which are being performed into this research paper and comparative analysis of the hypotheses is widely explained into the research paper which also widely discussed about the two types of hypothesis which are being related to the objective in order to perform the desired tests. This research paper will also help the reader as well as the business personnel in attaining all the knowledge about creation of the dashboard and its importance into the business purposes which will help them to raise the performance of their particular business by creating a powerful dashboard.
Reference List
Journal
Alcivar, N.I.S., Gallego, D.C., Quijije, L.S. and Quelal, M.M., 2019, March. Developing a dashboard for monitoring usability of educational games apps for children. In Proceedings of the 2019 2nd International Conference on Computers in Management and Business (pp. 70-75).
Amin, A. and Valverde, R., 2017. Using Dashboards to Reach Acceptable Risk in Statistics Data Centers Through Risk Assessment and Impact. In Engineering and Management of Data Centers (pp. 41-72). Springer, Cham.
Amin, A., Valverde, R. and Talla, M., 2018. Risk Assessment, Impact Analysis and Control Methodology Via Digital Dashboards in Statistics Data Centers.
Becerra-Alonso, D., Lopez-Cobo, I., Gómez-Rey, P., Fernández-Navarro, F. and Barbera, E., 2020. EduZinc: A tool for the creation and assessment of student learning activities in complex open, online, and flexible learning environments. Distance Education, 41(1), pp.86-105.
Burkhardt, J.C., DesJardins, S.L., Teener, C.A., Gay, S.E. and Santen, S.A., 2018. Predicting medical school enrollment behavior: comparing an enrollment management model to expert human judgment. Academic Medicine, 93(11S), pp.S68-S73.
Buvinic, M., Noe, L. and Swanson, E., 2020. Understanding women’s and girls’ vulnerabilities to the COVID-19 pandemic: A gender analysis and data dashboard of low-and lowermiddle income countries. Data2X and Open Data Watch. Accessed February, 2, p.2021.
Costa, C.J. and Aparício, M., 2019, September. Supporting the decision on dashboard design charts. In Proceedings of 254th The IIER International Conference 2019 (pp. 10-15).
Crisan, A., Fiore-Gartland, B. and Tory, M., 2020. Passing the Data Baton: A Retrospective Analysis on Data Science Work and Workers. IEEE Transactions on Visualization and Computer Graphics, 27(2), pp.1860-1870.
Davis-Kean, P.E. and Ellis, A., 2019. An overview of issues in infant and developmental research for the creation of robust and replicable science. Infant Behavior and Development, 57, p.101339.
Donohoe, D. and Costello, E., 2020. Data Visualisation Literacy in Higher Education: An Exploratory Study of Understanding of a Learning Dashboard Tool. International Journal of Emerging Technologies in Learning (iJET), 15(17), pp.115-126.
Ellis, G.D., Taggart, A., Lepley, T. and Lacanienta, A., 2019. Method for Monitoring Quality of Extension Programs: A Dashboard Construction Process. Journal of Extension, 57(1), p.24.
Fleming, J., Marvel, S.W., Motsinger-Reif, A.A. and Reif, D.M., 2021. ToxPi* GIS Toolkit: Creating, viewing, and sharing integrative visualizations for geospatial data using ArcGIS. Medrxiv.
Ghaffar, A., 2020. Integration of Business Intelligence Dashboard for Enhanced Data Analytics Capabilities.
González-González, M.G., Gómez-Sanchis, J., Blasco, J., Soria-Olivas, E. and Chueca, P., 2020. CitrusYield: A dashboard for mapping yield and fruit quality of citrus in precision agriculture. Agronomy, 10(1), p.128.
Kaufmann, M., 2019. Big data management canvas: a reference model for value creation from data. Big Data and Cognitive Computing, 3(1), p.19.
Mena, M.A.C. and Isaias, P.T., 2019, January. Gathering Researchers’ Requirements to Develop a Learning Technologies Dashboard. In 12th IADIS International Conference Information Systems (pp. 51-59).
Mohammed, D. and Quddus, A., 2019. HR analytics: a modern tool in HR for predictive decision making. Journal of Management, 6(3).
Mora, J.M.L., 2020. Qlik sense implementation: dashboard creation and implementation of the test performance methodology (Doctoral dissertation).
Pitropakis, N., Logothetis, M., Andrienko, G., Stefanatos, J., Karapistoli, E. and Lambrinoudakis, C., 2019. Towards the Creation of a Threat Intelligence Framework for Maritime Infrastructures. In Computer Security (pp. 53-68). Springer, Cham.
Rouhani, S., Zamenian, S. and Rotbie, S., 2018. A Prototyping and Evaluation of Hospital Dashboard through End-User Computing Satisfaction Model (EUCS). Journal of Information Technology Management, 10(3), pp.43-60.
Saggi, M.K. and Jain, S., 2018. A survey towards an integration of big data analytics to big insights for value-creation. Information Processing & Management, 54(5), pp.758-790.
Tichem, L.W., 2018. Making a Statistics Netherlands (CBS) Dashboard: How a Communication Platform reflects an Ideological Stance (Master’s thesis).
Tsuchida, R.E., Haggins, A.N., Perry, M., Chen, C.M., Medlin, R.P., Meurer, W.J., Burkhardt, J. and Fung, C.M., 2021. Developing an electronic health record–derived health equity dashboard to improve learner access to data and metrics. AEM Education and Training, 5, pp.S116-S120.
………………………………………………………………………………………………………………………..
Know more about UniqueSubmission’s other writing services:
