CE888 Machine Learning for Causal Inference from Observational Data
Introduction
Language, causation, meaning correlation too are employed interchangeably nowadays, despite the fact that they might have a wide range of meanings. The word correlations denotes a shared link: when variables show a tendency of rising or decreasing, they are said to be correlated.
Economic term causation is used to describe the explanation including the impact, with said explanation serving as a sort of forerunner to the impact. The effect is linked to the explanation in a certain way. More as well, causality reasoning seems to be a procedure of formulating the conclusion regarding a “causal link” depending on conditions under which a result occurs.
The difference between correlations reasoning versus imagine creating though is that it calculates the responses of the consequences variables even though it is modified. The observable information is collected by the researcher, who is essentially watching the activity without interfering in any way. The researchers have no authority over the individuals or therapies; instead, they just observe the planned publicly recorded data observations.

Nevertheless, it is simple to deduce the behaviors, data, along with its results of what has occurred from observed data. It will be the capability to forecast the upcoming year, and it is therefore so significant in the pharmaceutical and other associated organizations. This report would also explain how to become able to use a variety of causative inference estimation methods, as a thorough knowledge of their main qualities. More though, this paper will help its build a sense of how causality reasoning relates with machine learning problems.
Data
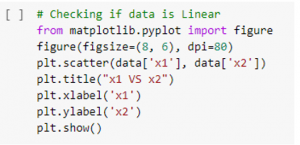
“Figure 1: checking linearity of data”
(Source: self-created)
It is the code of the google colab which helps to find out the scatter plot. This section clearly mentions the code level of the software. This section is also discussing the details of the import of the matplotlib.pyplot import figure (Prosperi et al. 2020). In this section it is also given the details of the scatter plot which is provided the two data is X1 and the X2.
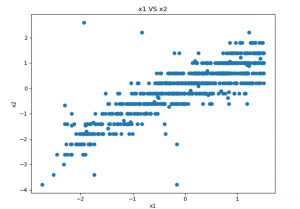
“Figure 2: Checking linearity of data”
(Source: self-created)
This section is also discussing the details of the scatter plot which is checking the linearity of the data. This scatter plot helps to find out the linearity of the data which indicates the relationship among the main two variables. This scatterplot is the best technique to indicate the non-linear pattern.
The data flow range such as the value of the maximum along with the minimum, will be also defined (Pearl, 2019). This scatterplot is very easy to understand and checks the linearity of the data. It is the two dimension scatter plot data. This phase is most essential for the reason it may use calculate for every numerical data. It might not use the different linear regression algorithm otherwise.
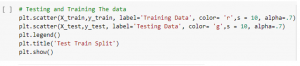
Figure 3: Testing and training the data
(Source: self-created)
In the above figure it is also clearly mentioned that it is the code level testing as training the data which helps to get the scatter plot. This section clearly indicates the color of the scatter plot. In this section it is also discussing the details of the test and train of the data and it also get the details of the split of the test train.
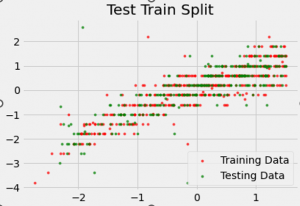
Figure 4: Scatterplot of data split
(Source: self-created)
This above figure defines the dataset for the testing as the training as the data split scatterplot. This section is also discussing the details of test data and the training of the data from exploring the dataset. This import database are the main two type of the provided data as test data of the dataset and the train data of the data set. The train constructed data to the machine learning algorithm and the applied test data for the module of the algorithm.

Figure 5: prediction plotting
(Source: self-created)
In this section it is also discussing the details of the code level test of the prediction plotting. This code level testing also analyzed the linear regression analysis which provided the color of the scatterplot of the prediction plotting. The color is applied for the x test, prediction level is equal to linear regression and the applied color is is teal.
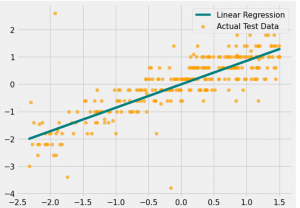
Figure 6: Linear regression plot for actual test data
(Source: self-created)
This above figure is a scatter plot graph which is the linear regression plot for the actual test data. Mainly it is to define the linear regression and the actual test data (Blakely et al. 2020). The linear regression is the green in the color with the line and the orange color is the actual test data from this graph. The linear regression is gradually increasing as compared to actual test data.
Methodology
The methods of image compression, cross-validation, plus regularization, linear regression may readily minimize overfitting during implementation. It is also the classifier of tree structure with many kinds of nodes. Phase of the decision tree split by the use of the information obtained. In addition, the decision tree aids in the estimation of alternatives (Chen et al. 2020). Logistic regression is amongst the most effective tools for resolving such issues, as it aids in the selection of many sorts of courses as activities. Decision tree algorithms were a kind of “qualitative design” which is permice any person to quickly layout options and analyze the expected result.
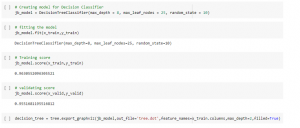
Figure 7: Depth of tree
(Source: self-created)
This above figure defines the decision classifier and the model fitting as training score as validation score of the depth of the tree.
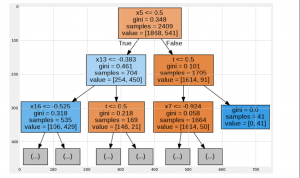
Figure 8: Decision Tree
(Source: self-created)
The branches as the decision tree are the only 2 methods that can be used to define as the decision tree. Machine learning employs a number of methods to discover how to partition a node over multiple sub-nodes. This formation of the “sub-nodes” improves the uniformity of “sub-nodes” that result.
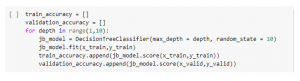
Figure 9: Initializing training accuracy
(Source: self-made)
The phrase train test divide refers to a method towards estimating performance output of a “machine learning algorithm” (Kreif and Diaz, 2019). These tests could be used to solve problems involving regression or categorization and develop “learning algorithms”.
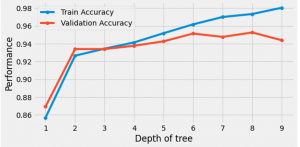
Figure 10: train and validation accuracy
(Source: self-created)
The phrase train test divide refers to a method towards calculating the performance of such a machine learning system. These tests could be used to solve problems involving regression or categorization. Validate split tests help to improve its precision by perfectly alighting the algorithm after each epoch. After completing the training stage, the validating divided test set informs both of the subject’s initial correctness.
The overall training set might not be too small, or otherwise the model would not be capable of learning (Alaa and Van, 2019). During machine learning, the classifier seems to be an algorithm that categorizes or arranges data into multiple or single class sets. In this situation, the classifier would be a predictive model. A regression also presupposes that the predicted factors along with it’s the result have a “linear relationship.” This model of linear regression is an excellent instance of regresor under this scenario. During machine learning, modeling refers to the process of designing a training algorithms to predict feature values and then verifying that on data set.
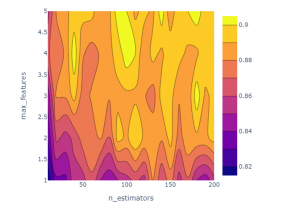
Figure 11: optimization of hyper parameter in 2D
(Source: self-created)
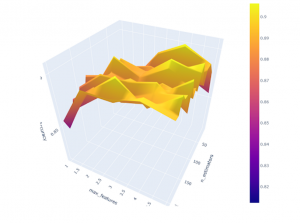
Figure 12: optimization of hyper parameter in 3D
(Source: self-created)
Hyper parameter optimization are utilized to fine-tune the searching algorithms inside this study. A system hyper parameters would be a representation that is external to the framework and whose utility could be determined from information. Hyper parameter optimization is widely used in methods to aid in the evaluation of mode variables. Hyper parameter adjustment is essentially accomplished by executing numerous trials in separate training tasks. An IPSW approach, also called “Opposite Propensity Weightage,” is employed in this research.
Conclusion
“Inverse Propensity Weighting” necessitates assumption, along with deficient areas, to correct the misclassification. Weighting has been used to complement the demographic profile across two or maybe more criteria to provide the paradigmatic sampling possible.
Weighting premise a dataset to be properly weighted such that the outcome more properly represents the community has been considered. This dataset was analyzed using the opens library to comprehend the structures as statistics to learn about the accessible data’s characteristics. The data has been analyzed to determine mean, median, as other upper quartiles that aid in evaluating options of ascribing different learning styles methods through regression as classifiers. The selection was for determination of the regression model is the arbitrary forest, which is more stable along with its produces reliable data than the logistic regression, plus various tuning methods were employed to retrain the tree.
Reference list
Journals
Alaa, A. and Van Der Schaar, M., 2019, May. Validating causal inference models via influence functions. In International Conference on Machine Learning (pp. 191-201). PMLR.
Blakely, T., Lynch, J., Simons, K., Bentley, R. and Rose, S., 2020. Reflection on modern methods: when worlds collide—prediction, machine learning and causal inference. International journal of epidemiology, 49(6), pp.2058-2064.
Chen, H., Harinen, T., Lee, J.Y., Yung, M. and Zhao, Z., 2020. Causalml: Python package for causal machine learning. arXiv preprint arXiv:2002.11631.
Dasgupta, I., Wang, J., Chiappa, S., Mitrovic, J., Ortega, P., Raposo, D., Hughes, E., Battaglia, P., Botvinick, M. and Kurth-Nelson, Z., 2019. Causal reasoning from meta-reinforcement learning. arXiv preprint arXiv:1901.08162.
Hernán, M.A., Hsu, J. and Healy, B., 2019. A second chance to get causal inference right: a classification of data science tasks. Chance, 32(1), pp.42-49.
Kallus, N., 2020, November. Deepmatch: Balancing deep covariate representations for causal inference using adversarial training. In International Conference on Machine Learning (pp. 5067-5077). PMLR.
Kreif, N. and DiazOrdaz, K., 2019. Machine learning in policy evaluation: new tools for causal inference. arXiv preprint arXiv:1903.00402.
Little, M.A. and Badawy, R., 2019. Causal bootstrapping. arXiv preprint arXiv:1910.09648.
Pearl, J., 2019. The seven tools of causal inference, with reflections on machine learning. Communications of the ACM, 62(3), pp.54-60.
Prosperi, M., Guo, Y., Sperrin, M., Koopman, J.S., Min, J.S., He, X., Rich, S., Wang, M., Buchan, I.E. and Bian, J., 2020. Causal inference and counterfactual prediction in machine learning for actionable healthcare. Nature Machine Intelligence, 2(7), pp.369-375.
Sharma, A. and Kiciman, E., 2020. DoWhy: An end-to-end library for causal inference. arXiv preprint arXiv:2011.04216.
Yao, L., Chu, Z., Li, S., Li, Y., Gao, J. and Zhang, A., 2021. A survey on causal inference. ACM Transactions on Knowledge Discovery from Data (TKDD), 15(5), pp.1-46.
Know more about UniqueSubmission’s other writing services:
