
CN7000 MSc Dissertation Proposal Sample
Project Proposal (CN7000 MSc Dissertation Proposal Sample)
The project is mainly considered with the detecting fake news with the python language. It is advanced project in the python it can detect which is the real news and fake news. It is mainly considered with the machine learning problem that is posed as the natural language processing. There are different kind dataset using for the analysis and prediction of the news in the application.
Here finding the fake using sklearn. Then initialize the Passive Aggressive classifier and fit into the model according to the process. Basically, all the news in the social media is not the real news it may fake news sometimes. The fake news can be identified using the advanced python very easily. Using the TfidfVectorizer concept it is used to find the term frequency that is number of times word appears in the document. Suppose it is having the higher value means it is appearing many times in the document. The IDF that is inverse document frequency is measure in the entire corrupt along with the message.
Literature Review
The fake news detection project is considered with the which is real information, and which is fake information that is find according to the service enhancement based on the utilization. The speed of the spreading news is considered in social media is very fast. The wrong communication is spreading is the various dangerous for the people that is needed to develop with the specific functionality and utilization of the process based on the measurement. There are many ways to claiming the news is fake or not ( S. Saad,2017).

First an attack on the factual points and the second is considered with the language that is usually considered with the searching process. The former is done through the substantial research according to the internet query automated systems. The natural language can place in this research process. In this process it is utilized with the specific process according to the functionality and measurement of each process that can provide the different kind of functionality.
The natural language detection is not easy task it is needed to map each character along with the segregation and analysis off each task. There are different kind of characteristics can be play in the important process and scenario of the measurement. The natural language pipelines if followed with the machine learning pipeline that is used for the specification and analysis of each task that is measured with the specific utilization and process of the various mapping system ( Q J. Sun, 2019).
The python is used for the development of the project in finding the process fake news identification along with the problem of measuring and recognize the machine learning problem posted as the natural language system. There are many datasets for this kind of application that is used for the specific analysis of the news based on the which category. In this classification concept is used for the prediction of the fake news and real news based on the matching process it is classified based on the label.
This may happen according to the utilization of the different kind of factors that is affected in the scenario. The wrong communication is spreading is the various dangerous for the people that is needed to develop with the specific functionality and utilization of the process based on the measurement. There are many ways to claiming the news is fake or not. In this the data is contain the 7500 news feeds along with eh two target label that fake or real. It is containing the title with the specific news piece that is measured with the different kind of utilization according to the measurement based on the analysis ( Sun,2020).
The acquiring and loading data are placed the importance access according to the utilization of different kind application according to the measurement and analysis of the process. The TF-IDF vectorization is categorized the word into the specific label if it is correct or not based on the analysis and mapping system for the benefit of the analysis.
The Counter vectorizer with TF-IDF transformer is considered with the effective matching process and based on the total count it is categorized into the label of the analysis for the betterment of the system and utilization of the different factors and methods for the analysis and process. This may need to analysis the various utilization and process of the TF-IDF value. it is used to measure the value according to the utilization of different product system for the analysis. This is needed to verify with the range of words that is mapped with the specific counting measurement.
Removing stop words is done for the removing the unwanted quotes and special symbols involved in the text and how this is removed and present with the only character like that it is needed to evaluate based on the mapping system of the utilization according to the functionality of the each process based on the measurement.
The natural language can place in this research process. In this process it is utilized with the specific process according to the functionality and measurement of each process that can provide the different kind of functionality.
Expected practical element output
Software tool
The python is used for this kind of process according to the functionality of detecting real or fake news. Based on the selected data set the software can be utilized in the proper way in the betterment of the process according to the classification of the real or fake news in the portal. For this the python is need to install with the following libraries in the pip.
Pip install numpy pandas sklearn
Like that using the coding for importing the sklearn in the pandas that is used for the easy specification according to the functionality and access of the measurement. For running the code need to install the Jupyter Lab and then using the command prompt it is done the process and execution of dataset. This following library file is need to implement according to the requirement of predicting the label ( H. Liu,2017).
Import numpy as np
Import pandas as pd
Import itertools
Like that it is discuss with the analysis and process of the execution.
Framework
The framework is considered with the following steps it is need to analyse and mapping with the specification of the process.
- Acquiring and loading the data
- Cleaning the dataset
- Removing special symbols
- Removing punctuations
- Removing the stop words
- Stemming
- Tokenization
- Feature extractions
- TF-IDF vectorizer
- TF-IDF transformer
- Model for training and verification
Like that it is considered the sequence steps.
Resource need
The following resources are need to implement and develop this software according to the specification and process.
- Python
- Jupyter Lab
- Data set
Like that the various resources are needed for developing this project and labelling the fake or real news according to the utilization of the process. There are different kind dataset using for the analysis and prediction of the news in the application. Here finding the fake using sklearn. Then initialize the Passive Aggressive classifier and fit into the model according to the process.
Prerequisite knowledge skill
The developer is need knowledge how to develop the coding using the python language. Then how to modify and reprocess the application based on the different skill. Before going into the developer first need to analysis what are requirement of project and how it can be used into the different kind process due to the effective application based on the measurement. This is considered with the effective development of the project.
Able to develop the coding and importing the sklearn in the pandas that is used for the easy specification according to the functionality and access of the measurement. For running the code need to install the Jupyter Lab and then using the command prompt like that prerequisite knowledge is used in the given process ( Duan,2020).
Gantt chart
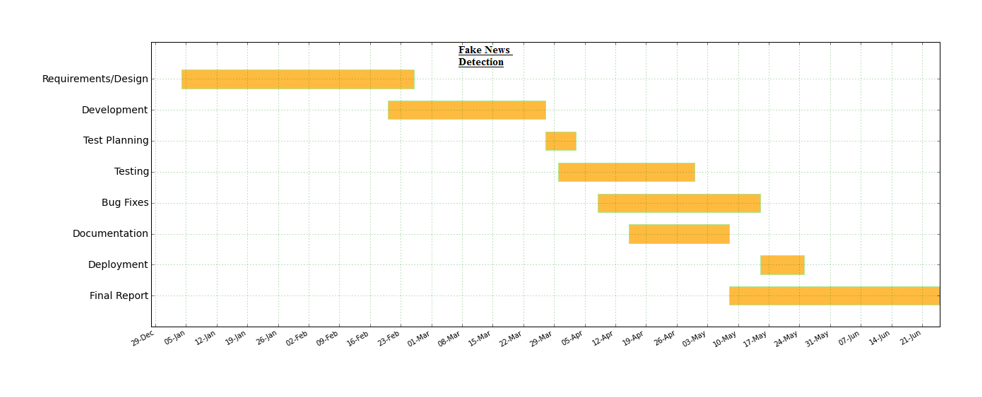
The following chart is shows the various process involved in the project development phases of the fake news detection system according to the different kind of responsblity. This is one of the planning strategy that is used for the effective analysis project status and this is support to improve and complete the project in time then it is mapping with the various analysis and process.
References
H Ahmed, I Traore and S. Saad,2017. “Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques[C]”, International Conference on Intelligent Secure and Dependable Systems in Distributed and Cloud Environments.
Q J. Sun, 2019.A Machine Learning Analysis of the Features in Deceptive and Credible News[J], pp. 1-2.
H S. He and GZ. Sun,2020. “Fake news content detection model based on feature aggregation”, Journal of Computer Applications.
K Shu, A Sliva, S H Wang, J L Tang and H. Liu,2017. “Fake News Detection on Social Media: A Data Mining Perspective”, SIGKDD.
- Wei, J. Ye, Y. Yan and L. Duan,2020. “Identification of true and false news,” 2020 2nd International Conference on Information Technology and Computer Application (ITCA), 2020, pp. 564-569, doi: 10.1109/ITCA52113.2020.00124.
Know more about UniqueSubmission’s other writing services:
