Dataset Using Semantic Data Technology Assignment Sample
Introduction
The new era faces modification in each sector as a result the current technique in data linking has changed from storing it manually to an automatic data updating. In this report, a database of school management is going to be created with the help of semantic data technology. This application helps to get the data to be processed in a computerized way as it deals with the data on the web.
This can help in establishing the reaction between systems and applications. RDF (Resource Description Framework) is used to create descriptions of the dataset. A Graphics User Interface (GUI) is going to be designed to show the data linking is working for a sample dataset of school management like dealing students, staff, teaches, subject, school with the relations in between them. A design of the whole system is going to be shown below as to execute the working functions in between the interface and the semantic dataset.
Objective
To create a database for web application of school management system using semantic data analysis

To design ontology for creating a database and developing a school management system
To build a school web platform of school management system using school information dataset with semantic analysis technology
Aim
This project aim to develop a Semantic analysis technology using dataset describing the development and implementation of a school management system.
Concept
A semantic dataset is needed to be created with the help of SPARQL on the framework of RDF. The dataset is going to be done on the integrated development environment of the Protege. RDF schema would be used to create this database to define the classes, relationships as well as properties of each entity for school management.
Web Ontology Language (OWL) offers a language of understandable structure in web-based ontology. According to the author McCrae, J.P. and Buitelaar (2018), this database is created mainly to link them in between the entities to show the working functions of the total school management of how it is working. A user interface needs to be made to show the whole work done. This user interface is done with the help of JAVA.
This interface has to be linked with the dataset to give the proper working as instructed. This database wants data to be stored in a computerized way and the main advantage in using this semantic bas4ed web technology is to get the data updated in an automatic process.
This whole interface shows the data as authenticated but this data storage technology deals with a high functioning interface with a function to auto-update with linking data available on the web. As cited by Traverso et al. (2018), the semantic web technology is able to get the information integrated from distributed unstructured data and its sources.
This can count on the authenticated data to be stored because this whole process worked in a computerized way and without any human intervention. This also gives a concept of being the data to be flexible and interconnected. Interlinking between the data is possible as per the semantic web-based technology as this deal with the technology RDF and OWL. This whole technology gives the idea of categorizing data with processing by a set of methods and tools provided by Protege.
Design
In order to run the SPARQL RDF queries, initially, the database must be created and the corresponding dataset has to be relevant to the database. In this particular report, a school database has been chosen for initializing data on the database and running the SPARQL RDF queries on it.
In order to execute queries within the corresponding dataset provided in the database, a developer needs to have sufficient knowledge of triples. Before proceeding towards the queries execution, triples consist of subject, predicate, and objects. SPARQL is a W3C standard. SPARQL stands for SPARQL Protocol and RDF Query Language (Wang, 2017, p. 9). The Protocol part is the part that is used for writing queries to the programmer.
The developer runs programs that pass sparkle queries. For executing queries a three-part statement called triples has to be generated by using datasets. For example, student studentID and “st100”. These three parts are called subject predicate and object respectively. The terms are equivalent to an entity identifier, an attribute name, and an attribute value.
In this protege software subject and predicate are represented by the help of URI which is almost equivalent to URL but unless URL, URI is not a locator. URI stands for Unified Resource Identifier. These URIs help to show that student from a specific database that contains a student entity set.
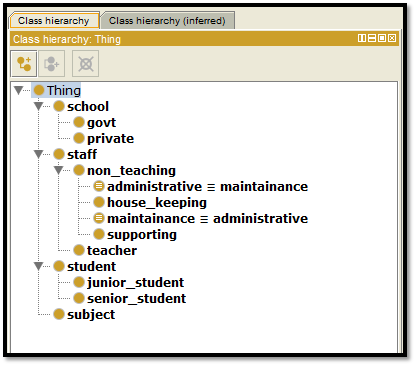
Figure 1: Ontology design of Classes
(Created by Learner)
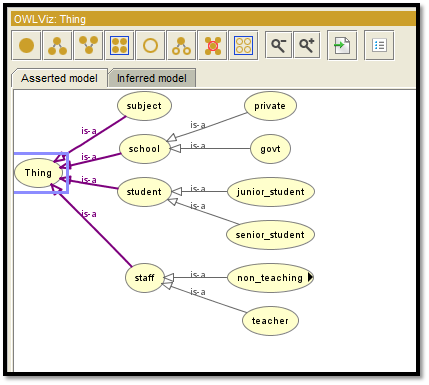
Figure 2: Ontology design of OWL Viz 1
(Created by Learner)
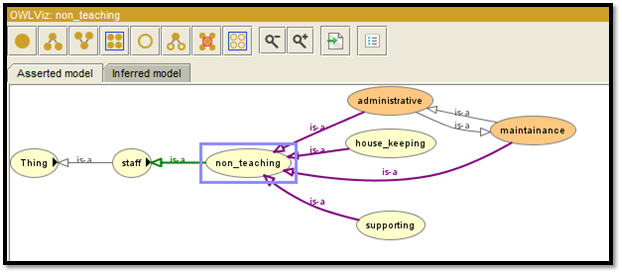
Figure 3: Ontology design of OWL Viz 2
(Created by Learner)
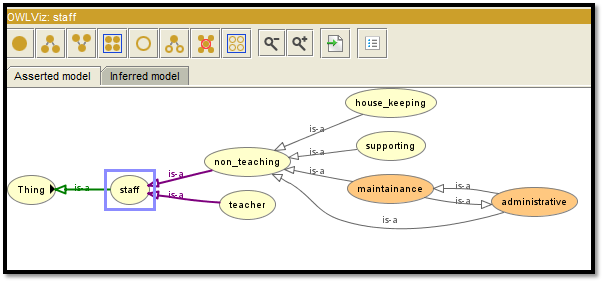
Figure 4: Ontology design of OWL Viz 3
(Created by Learner)
Every part of the triples can produce URI. The object value part can also be set with a URI. For simplification, the URIs are abbreviated to generate abbreviated URI which is used to set the identifier. The SPARQL helps the user to make queries on the key value of the data.
This language is similar to the NoSQL database design which is similar to MongoDB. The SQL relational database using RDF queries are three segments named as subject predicate and object. This software called protege gives exposure to writing SQL-based codes on the NoSQL format.
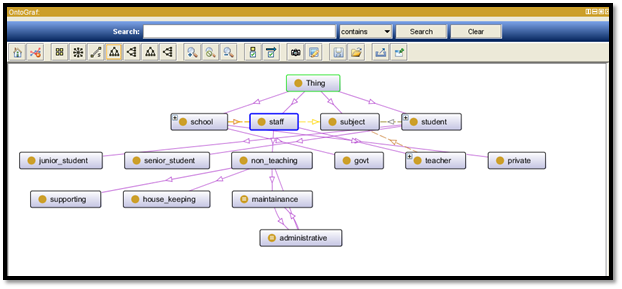
Figure 5: Ontology design OntoGraf 1
(Created by Learner)
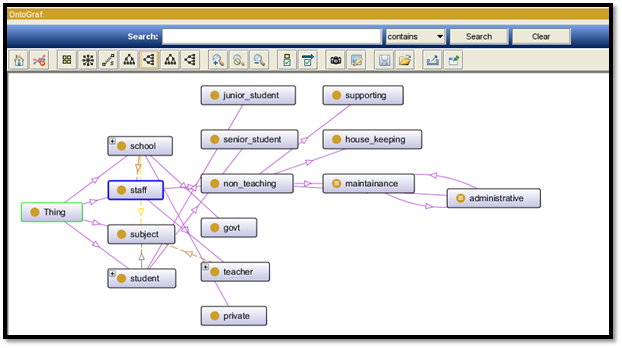
Figure 6: Ontology design of OntoGraf 2
(Created by Learner)
NoSQL format writes the SQL code in a slightly different format which does not use the SQL query implementation on the SPARQL query tab. The SPARQL query runs with the help of setting prefix where the abbreviation of the URIs is being stored to locate the subject or predicate or object. Most of the work is done using the execution of the SELECT query.
The select query is the most popular in the SPARQL RDF query language. The select query is executed by using the where clause within it. An example of a query is written using select query. A generalized query using select format is shown following, SELECT ?subject ?object
WHERE { ?subject rdfs:subClassOf ?object }.
This query is going to run when the programmer will clearly mention the subject and object of the class and also mention the rdfs:subClassOf for specifying the class name where the subject and the object are currently residing. Before proceeding with the select query the prefix of the SPARQL query has to be mentioned on the top of the SPARQL query tab. In order to understand the SPARQL query, the programmer needs to look for the where part (Pejić Bach et al. 2019, p. 1279).
The part is mainly responsible for describing which of the triples have to pull first. In these queries, the objects can be any of the data types. The data types are more likely strings. Other than a select query in SPARQL more queries can be useful in the case of doing RDF-based SQL queries. Other types of queries are asked, DESCRIBE and CONSTRUCT. Sparql also offers for executing sub queries, aggression, and negation.
These queries are used to create values for expression, value testing for extensible patterns, and construction of queries by running RDF graphs. The output of SPARQL queries is nothing but the outcome of the RDF graphs. The main difference between SQL and SPARQL-based queries is, SQL queries are executed by using structured query language codes whereas the SPARQL queries are more likely to follow the NoSQL format.
However, both these languages give the user the ability to create, merge and produce structured data by using the query language. SPARQL allows the user to create this structure by using web-linked data and SQL allows the user to create this structure by using tables and establishing relations within the tables.
There are many similar operations between SPARQL and SQL queries such as minus, union, and many more. These operators are used for removing or adding some set of instructions within the program. However, SPARQL queries are mainly used for semantic datasets whereas SQL queries are used for normal datasets. The semantic data model is a process of orienting data in order to show the data in a specific logistic format.
The semantic data types are used for data like number, string, Date Time, and many others (Behley et al. 2019, p. 9297). The semantic web allows providing a general framework to share information and use the same information again for the application or the organization.
This section is going to give an elaborate description about the working procedure of semantic dataset using SPARQL on RDF or RDFS. The ontology selected on this particular report must be suitable for semantic data technology. Using owl ontology a report has been prepared where datasets are taken based on a replica model of the database similar to the school database.
The software used for preparing the task for the database is called Protege. This software is meant for executing SPARQL based queries and running the database which allocates semantic dataset successfully. This software offers an interface where developers can add things which are equivalent to the entities in the school database (Auer et al. 2017).
For this particular project a school database is created and things or entities are given as student, staff, subject and school. Inside the staff table based on the real architecture of any school non teaching and teaching staff are being added. Again non teaching staff are differentiated among administrative, house_keeping, maintenance, and supporting. Student table is again subdivided into junior and senior.
School table is divided into government and private schools. Some of the description has been initiated under the administrative and maintenance section and in between the staff and the student.
For the first description equivalent to description has been selected and for the next two tables disjoint with description is being selected. In order to proceed with the work using Protege software class hierarchy must be initiated. The class hierarchy has been declared by the help of using code written on any text editor.
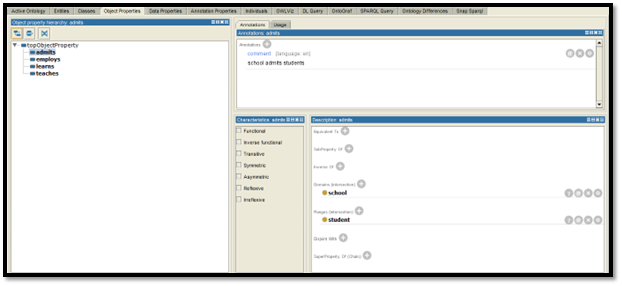
Figure 7: Ontology design of Object Properties
(Created by Learner)
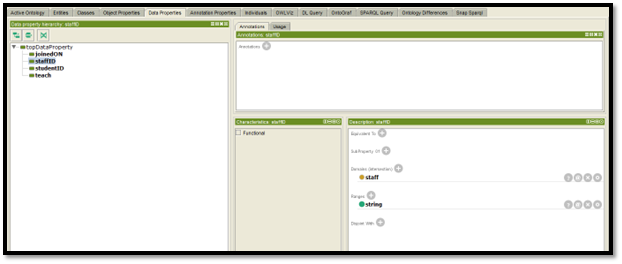
Figure 8: Ontology design of Data Properties
(Created by Learner)
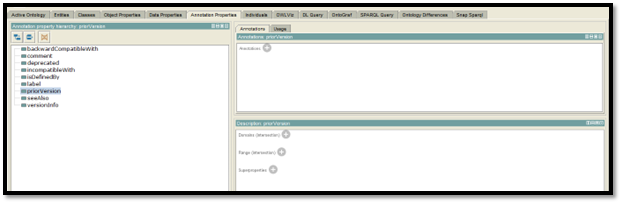
Figure 9: Ontology design of Annotation Properties
(Created by Learner)
After proceeding with class hierarchy, next a developer needs to annotate the working criteria of each of the tables present in the database. For example, school class is annotated as “this class denotes the school”. After distinctly mentioning the classes on the school database, the OWLViz tab on the software provides a graphical interpretation to view the workflow. After this part, object properties have to be declared (Bindhu, 2019).
On the object properties design the relations between the classes. The objects selected for this particular project are admits, employs, teaches, and learns. These objects are also set to some specific annotation. For example, in the case of teaching an object, “teacher teaches the subject”.
After that, the description domain and ranges are being selected on each object to understand which object is working on which class. Then after doing the object creation part datasets have to be added. As of now, the dataset inputs on the database are only for student school and teacher class.
The data has been declared and after initializing any data suitable data type and domain of the needs to be selected. There four instances are created studentID, teach, joinedON, and staffID. JoinedON is a DateTime type of variable. Other than this all the other instances are of string type. In order to input data to the studentID, one has to go to the direct instance property of the interface and add values within the input bar.
The dataset of the school management has been done here with the help of protege as this application runs with SPARQL query for RDF (Resource Description Framework). This framework depicts the resources that are available on the web and this also stands for the data interchange. This school management dataset has been taken here to set up the whole work in semantic web-based technologies.
According to the opinion of Abdelaziz et al. (2017), RDF can show the relationship between the attributes in a graphical representation. A relational database has been created with the help of Protege which consists of SPARQL query language. The database is done with having the successful query to put the data into it.
In the table of the dataset school, the rows are denoted as subject whereas columns are denoted as predicate and information is the object as identified in an RDF data model.
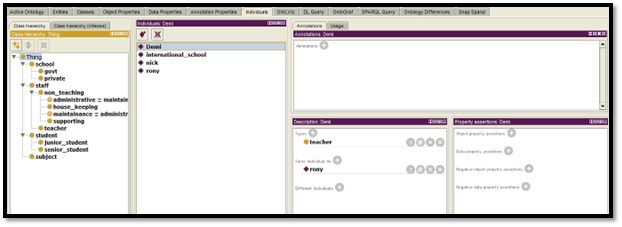
Figure 10: Ontology design of Individual -1
(Created by Learner)
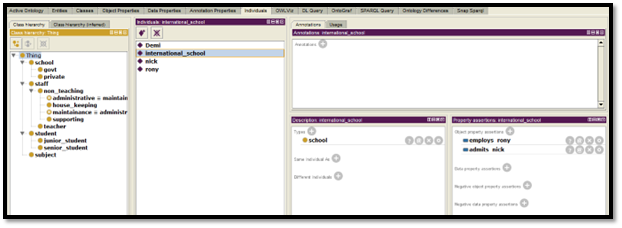
Figure 11: Ontology design of Individual -2
(Created by Learner)

Figure 12: Ontology design of Individual -3
(Created by Learner)
The data is needed to be put in the table to show the tree as a representation of the total relational database. This framework gives this information of school in a simple but expressive manner. The subject and the predicate are actually represented in the table as Uniform Resources Identifier (URI).
The subject, predicate, and object make triples that help the queries to run well. The identifiers help each entity or attribute to know what it is as this URI can identify objects; it cannot give addresses or locations like URL. The keywords or the clauses in the query help to fetch the data as per the requirement.
This whole dataset was created with the help of semantic web technology to connect this information set with a Graphical User Interface (GUI) that permits any data to be modified as per the need.
The Graphical User Interface has been created to use in the future to help in increasing the data integration process. The dataset is implemented with a beautiful schema and the user interface helps to implement in front of the user. Java is used as a programming language to build this graphical interface to provide assistance to the user of this dataset to be modified as per the school’s need.
JAVA is written in the Apache Jena to implement the interface and later to connect the dataset with the interface. According to author Bonifati et al. (2020), the interface, made with the help of JAVA, gives a look to this interface with having the facility to provide the graph in an extended one. As RDF offers the information to be merged easier, the interface provides the same to give any input in it as to create a semantic web-based system.
JAVA provides the interface to be simple as one can know and understand the functions in it. As it is object-oriented, it always serves a system to be oriented by a set of objects which helps this dataset to be connected and working. This whole representation is made with SPARQL and JAVA to get the whole dataset in a simple form with simple processing technologies.
Implementation
In order to implement the SPARQL query for a suitable semantic-based database, datasets need to be created under the corresponding database. In this particular report, the database selected for running the queries is the school database.
The school database is a simple database with 4 classes within it. The database is created with 4 entities like subject, student, staff, and school. Again the staff is also defined by two sub-classes which are non-teaching and teaching.
The non-teaching staff is again sub-classified with 4 more subclasses. The subclasses are administrative, housekeeping, maintenance, and supporting. Next, the student class is defined as junior and senior of the parent class. School class is subdivided into govt and private class. Then after that, the description is added to the student and staff class.
The staff class and student class also have a description which is called a “disjoint with” description. After visualizing the creation of the entire database created properly, then the annotation is given by adding an annotation on the school class that “this class belongs to the school class”.
Again another description is added to the administrative and maintenance class that administrative and maintenance are two equivalent attributes (Ibrahim et al. 2019, p. 116). We can check the entity-relationship model similar to the SQL relationship model in the inferred hierarchy tab. Each of the classes holds each entity-relationship model corresponding to the database. The class school then starts with the reasoning for executing the following tasks successfully.
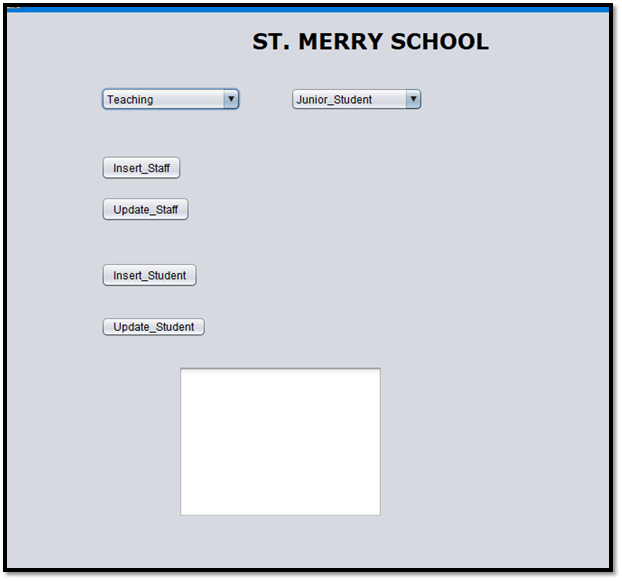
Figure 13: User Interface Design
(Created by Learner)
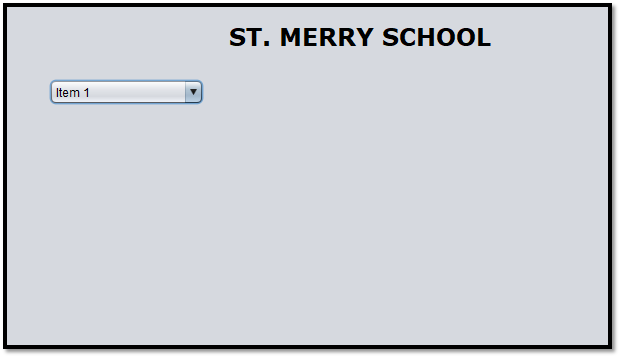
Figure 14: User Interface Design
(Created by Learner)
Now coming to the RDF format, RDF is formally known for a directed, labeled graph data structure that represents information on the web. This specialization denotes the syntax and semantics of the SPARQL queries to run the RDF-based queries. Sparql is used for structuring data from various sources, sometimes the data in the directory is stored as RDF and viewed also as RDF.
Sparql consists of an optional portion of executing the optional graph along with the disjunctions and conjunctions. Sparql is again going to run the query before running the execution steps. The object properties are being initiated to the addition of the objects in the additional panel. The class hierarchy is run by the code,
student
junior_student
senior_student
staff
non-teaching
supporting
house_keeping
administrative
maintenance
teacher
school
govt
private
Subject
The object properties added to the object field are executed from the data property hierarchy. The added objects on the school database are taught, learned, employ and admit. The relationship is included after the initiation of the objects in the property section. The student learns from the teacher.
The teacher teaches the subject. The employees are employed at the school and the students are admitted to the school. These are the specified structure of the relationship used at the time of creating the database and adding the objects to their corresponding subjects. The subjects are staff, school, student, and subject. Under the subjects, the predicates and objects are being added.
After creating the objects on the object property the domain and ranges are being added to each of the objects. For example, the learn object is defined as the domain class of the student, and the range selected for the learn object is the subject. Next, the property hierarchy is selected for the data, these are staffid, student id, teach, and joined on.
The data types selected for each property are strings except the joined data type. The joined data type is selected as DateTime. Again in the description section, the properties have to initialize their domain and range name.
The domain name for the joined on a property is set as a student and the range is selected as the DateTime. Student id has selected the domain as a student and the range selected for this particular property is a string. Staff id is selected to the domain as staff and the range selected to the staff id is a string.
The selected domain for the teach property is teacher and the range selected for the teach property is a string. After that, the database gets the input for each entity identifier. In order to input information within the dataset, the respective class has to be selected and select the direct instances section and input the field with suitable data. After that redirect to the object property and give the input to the object property as well to create a relation between both of the data sets.
A semantic dataset has been created to have a simple ontology model which helps to know about each relationship between the entities or attributes in a graphical representation. The RDF framework helps to get the mixture of a common vocabulary to easily identify the semantics in the query language.
This can give a structure of a proper schema for the whole dataset to build and map the relation between each identifier. This provides a brief knowledge about the dataset to know the working functions and relations. This system also assists in having metadata labeling which makes this system more meaningful. As this structure helps in understanding the dataset, it also gives relations and inputting data to each attribute it also makes this simple.
The computation provides each data’s update as this system has the ability of an automation process. Based on the statement of Lefrançois et al. (2017), the dataset is done within the RDF model to get all information about with labeling of metadata to each entity. With the help of these semantic web technologies, a schema of it has been made. This system gives trust as this can be manipulated for being this application to be opened sourced.
The OWL has been used as the language to describe this relationship as a complex and rich one. RDF, RDFS, SPARQL are included in it as a stack. This ontology is mainly used for providing descriptions in online mediums. In this process, RDF assists these data to be modified and interchanged online also because this semantic web system deals with linking information or dataset on the web.
The JAVA is used as a programming language to set up a Graphical User Interface as in a GUI to implement all the queries to provide data as an input with the help of a simple interface. JAVA assists this interface by providing a frame, a panel with a keyword to JPanel.
This interface is needed to get the linking with the dataset to show its proper working with each function as the query needs to be run successfully. In this whole system, a search button is there to search any data to fetch from the dataset and it would be auto-updated according to the user. Semantic web shows a relation between each entity and this interface helps to get the storage of that information in each identifier.
Linking with the objects is the main motive to have this full implication done.
The semantic web is the latest technology that provides logic, trust, and rules to it. As this gives the system trust in having the data to be secured, it uses the technique to hide data from any third party inclusion is nothing but cryptography. In this whole process of a school system user interface, it states the simple functions to access each of the attributes to show or search data, an update to it if required and modification like deletion if needed.
Analysis and Deployment
Semantic web technology is a technique where a user can create a dataset for storage on an online medium. This system has the ability to get mixed vocabularies as well as axioms to handle datasets. As per the statement of White et al. (2019), the available data are linked and authorized by the methods such as SPARQL, RDF, and OWL.
Apart from it, RDF has done the most important step to encrypt the data as this whole dataset deals in an online medium. This does the functions of retrieving data from particular information set online. It is the query language that helps in modifying each data in the storage of the school management database. In order to make a query, the SPARQL makes it to get this run successfully and if it runs then the data goes to the RDF database.
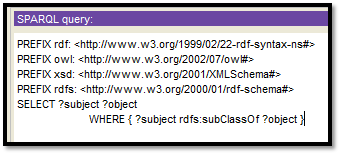
Figure 15: SPARQL Queries
(Created by Learner)
SPARQL is a draft query language that derives from RDF and it gives a popular use of it as this provides the linking better in entities of a dataset as in the school here. The SPARQL queries should be run successfully at the backend in order to ready a dataset. The queries are made for the information to have input. An interface is made to have input as a given data to a particular database as in the school management here.
As this data is vital for the school to maintain for future use this should be highly essential to get all the information as encoded. The data can give a detailed understanding to all the entities of how it works like a function. This function assists to get data to make the ontology properly. This whole data process to get them stored on the web needs an interface with an available understandable function to the user.
JAVA is successful in making that implementation about storing data at the right place.
In order to have the analysis of the website, it uses JAVA programming language to make the console where the data can be put to the database. The database is handled by the interface to have all the information in its perfect place.
Some keywords like JFrame, JPanel are used to make the layout with a border to give a skeleton of the whole interface. In the interface of the school management system, JAVA plays an important role in having a colorful graphic that assists the users to do the operations. As per the dataset with the web technologies of semantic, RDF framework gives the hiding and encryption of the information set as to embed details of staff, student, and other staff.
According to the opinion of Beierle et al. (2017), any programming language that helps to build a graphical user interface assists to ask data to have it or make it find it from the console. In this interface, details of new students can be added for keeping the information for a long time as this technology assists the data manipulation in an online medium.
The database is created to store information in an advanced process by applying the semantic web technology to it and to make it operate as fully functional, and an interface by implementing JAVA is created.
This section is going to discuss the analysis and deployment of the user interface in java by using apache Jena. The user interface is going to execute on the NetBeans IDE using apache Jena as apache Jena can run RDF query languages. Apache Jena is a framework to run java programs in order to build a semantic user interface application.
Apache Jena provides an environment for the programmers to include SPARQL, RDF, RDFS, and OWL query languages. Jena is a Java API which is used to create and modify RDF-based queries and graphs (Alsanad et al. 2019, p. 49353). Jena has object classes that help to entitle resources, graphs, literals, and properties. In order to proceed with apache Jena, a developer needs to have a clear knowledge of the use of apache Jena.
RDF is more precisely known as Resource Description Framework which helps to define resources. RDF consists of properties and literals. The RDF model consists of subject, predicate, and object. These are combined called triple. Each triple is used in the database to represent data within it. Jena provides some built-in functions to represent a user interface.
The object of the RDF model can be literal or resource. In order to return an object having data type as RDFNode is done by the getObject() method. Jena gives a provision to read and write both in RDF which is similar to XML. In order to perform connectivity of frontend and backend using apache Jena in the NetBeans IDE, Jena gives the provision of SPARQL over JDBC.
In the process of creating a user interface by using java NetBeans IDE, the school data has to be prepared first after that the user interface is created to provide the user a platform to fetch data from the backend and display the information in the user interface. In this particular report, a School database has been created. The database has classes like student, staff, subject, and school.
After creating the classes we need to create individual data properties and object properties. After installing each data property and object property, our next focus is to create the user interface application using the owl file (Reitemeyer and Fill, 2019, p. 214). The NetBeans IDE is the version of 8.2v. Netbeans software starts with creating a new project on the file menu, on the new project section select the java category, and on the projects section select java application and click “next”.
After selecting the project name and clicking finish, the project is created. The source package will create a new source package, which further requires the class name, and then selecting finish will be the completion of the new project.
A new window will pop up where two platforms are separately mentioned as design view and source of the code. On the source platform, the programmer writes the code and in the design view section, the frontend user interface is shown.
In order to create a successful connection between frontend and backend the programmer initially prepares the design view by dragging and dropping the tools from the palette section. In this particular project, the design view consists of some basic tools (Satyamurty et al. 2018, p. 235).
At the top of the design page, the name of the school is shown by using a label control. Next, there will be student and staff dropdown control which consists of the subcategories of student and staff.
The student class is categorized as junior and senior. Staff class is categorized as non-teaching and teaching. Subclass junior will redirect to a new page where junior students have the label of data to be entered are Student ID, Student Name, Admission Date, Subject, Class, and Year.
The next subclass is considered as senior students which also have similar sets of labels and their corresponding text boxes. Additionally, within these two pages, there are two buttons on each page which are named as insert and update (Schekotihin et al. 2018, p. 341). The insert button will help to insert new data within the database the on button click option will enter new data with the database in the particular student table to reflect any student details who get admission to the school.
The update button will help to update the current database by updating any of the fields present in the student table. For example, if any student is promoted to any class then the update button will update his or her class to the next class. Staff table data is also controlled by the user interface created using java. The staff table is again divided into two different categories: non-teaching and teacher.
The required fields or labels for non-teaching categories are Staff ID, Staff Name, and Position. The teacher class has fields such as Staff ID, Staff Name, Subject, and Class. Within the subject class, the subjects are mathematics, physics, chemistry, biology, and english.
In order to connect the owl file with the user interface, a predefined openOWL. Java file must be added to the project first (Zeebaree et al. 2019, p. 25). After adding the all required file to the source folder and adding openOWL. Java file, we are ready to connect the user interface with the backend owl file.
Critical Reflection
A database is the best option to store data with the need to use any information in the future for any requirement. The current times have provided the scenario of having this full implementation done on a web-based system like in semantic web technology.
Now any institute like school, any business sector wants to make their counting on their respective entities. These things help this system to know and be certain about their every action as well as to make new planning according to the existing dataset. This whole dataset is made in the Protege as it is based on RDF, RDFS. In this application, ontology is created to show the users the relationship with the entities.
These entities are there to get to know and understand about each data to update or any modification like insertion, deletion.
The dataset is created as arbitrary information set like school management where the queries would run on the basis of what a user wants to see or do with that particular information. This can give the example showing the data to be connected, disjointed, and sub-classified to get everything in manner. This manner needs to be started or run as ‘Start reasoner‘ as that is an important step to get each data to become synchronized.
These steps make this data storage perfect as to know the vision can be shown with having the relationships in it. SPARQL gets this application to work by storing and retrieving data in RDF format. Based on the influence of Zeebaree et al. (2019), this query language helps this particular dataset of the school management to be accessed within web linked data. This consists of a concept of metadata that holds information of the actual one. This language helps this data to be considered as the triples.
The triples in an information set count as the subject, predicate, object where this information is differentiated. The rows are denoted as the subject, columns as a predicate and the objects are considered as the value that is put in the dataset. Information is linked together as dependent on each other like in this schema students are interlinked with admits, subject, teacher, and other entities.
As per the statement of Traverso et al. (2018), the dataset of the whole setup can show the overall data attributes with its provided values. SPARQL provides too many advantages in having the data encrypted as to hide and secure information from others.
This language provides the queries of having SELECT, CONSTRUCT, ASK and DESCRIBE for the specific dataset to be fetched for a particular reason. As these reasons are successful to meet with a proper manner to show all the questions, the queries are done properly to get all the needed modifications.
Mainly the idea of the overall system is done with the help of having the queries on SPARQL that helps this overall design to a linked one. Another application like an alternate approach of this as in SQL provides the data storage in a relational model. SPARQL is a far better approach according to the SQL for any certain database to have an entry to the system.
The semantic applications are best to get the data in a relational database or a web-linked one to have it secured. The final result is better to have them with high-speed access to get all information. According to the opinion of Rinaldi and Russo (2018), SQL and SPARQL are somewhat different as per their data type like integer, char, and name as string and subject, predicate, object, identifiers respectively. SPARQL helps to have a format in RDF to store data whereas SQL does provide a normal allocation of the dataset.
The SPARQL and SQL have different types of attribute styles as whole data is dependent to be inserted as per their attribute types. In this whole dataset if SQL has been used to get the data to be stored then the database has become a relational database. The database is also an effective one as it is used with semantic web technology.
The attributes are normal as a set of strings in a SQL based data storage whereas SPARQL has done the best of its storage technique like insertion with a query-based language by linking with a semantic web. In order to get any data asserted to the dataset, the interface has been made based on the language of JAVA, an object-oriented programming language.
The interface of the school management has made for the insertion of any updating like changing in any attribute or data type has done on the basis of their data type and attributes type.
In this segment of the whole dataset, SQL provides a set of attributes and values as a pair but SPARQL has given the data as triples like a set of the subject, object, and predicate. As cited by Meroño-Peñuela (2017), the interface is made as per the requirement of the database to put the values in because the console of the data management system gives the users as per the institution’s choice.
Managing data with SPARQL to get connected with the information is highly efficient compared to other semantic query languages. The things are getting represented in a graph like with modeling to RDF in SPARQL. This serves the complex model of data representation as this can have the ability to fetch any information from an unstructured semantic web data design.
The interface to have the SPARQL in the back to get the data to be stored helps this whole system to run with a flow. Data Storage in the relational database is not so efficient nowadays to make everything stored in this style as web-linked data is needed to get automation of any operations.
In the whole representation, Java is suitable to make an interface as it is easy to have options like what the console wants. In other languages, it can be somehow tough to get a graphical user interface to be implemented with this dataset by applying semantic web technologies.
As per the citation of Hitzler et al. (2020), this web technology has given the option to get the data to be designed in a linked and connected manner whereas other patterns in semantic technologies provide relational data modeling.
Conclusion
This section describes a conclusive overview of the entire project. In this section, a complete project is going to be concluded and any recommendation if possible within the software work is going to discuss this part. This work is completed by using protégé, Netbeans IDE, and apache Jena software.
Protégé software is used for creating a database of the semantic data using SPARQL RDF query language and initializing new queries to fetch desirable outcomes from the table. In order to establish the user interface, Netbeans IDE and apache Jena are required to create the frontend design view and create backend connectivity with the SPARQL dataset.
This report deals with a school database, where basic classes are added to the database like student, staff, subject, and school. In the user interface part a basic design view is created for inserting new entries and updating the table with the help of java and finally connecting the user interface application with a database which is an owl file. This is recommended that the user interface can be more realistic by adding some extra features like the delete option.
References
Abdelaziz, I., Harbi, R., Khayyat, Z. and Kalnis, P., 2017. A survey and experimental comparison of distributed SPARQL engines for very large RDF data. Proceedings of the VLDB Endowment, 10(13), pp.2049-2060. Available at: https://dl.acm.org/doi/abs/10.14778/3151106.3151109?casa_token=veaODSrU8C4AAAAA:l_bsDKI4S9SAYruvSt4FrnqPIBYeMVidfOxTPA_Ox9rd4v-Pjl3BOWnUyo1BIihlHpQARrJqCLka
Alsanad, A.A., Chikh, A. and Mirza, A., 2019. A domain ontology for software requirements change management in global software development environment. IEEE Access, 7, pp.49352-49361. https://ieeexplore.ieee.org/abstract/document/8684236/
Auer, S., Scerri, S., Versteden, A., Pauwels, E., Charalambidis, A., Konstantopoulos, S., Lehmann, J., Jabeen, H., Ermilov, I., Sejdiu, G. and Ikonomopoulos, A., 2017, June. The BigDataEurope platform–supporting the variety dimension of big data. In International Conference on Web Engineering (pp. 41-59). Springer, Cham. Available at: https://link.springer.com/chapter/10.1007/978-3-319-60131-1_3
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C. and Gall, J., 2019. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9297-9307). Available at: http://openaccess.thecvf.com/content_ICCV_2019/html/Behley_SemanticKITTI_A_Dataset_for_Semantic_Scene_Understanding_of_LiDAR_Sequences_ICCV_2019_paper.html
Beierle, N., Kruse, P.M. and Vos, T.E., 2017, October. GUI-Profiling for Performance and Coverage Analysis. In 2017 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW) (pp. 28-31). IEEE. Available at: https://ieeexplore.ieee.org/abstract/document/8109243/
Bindhu, V., 2019. Biomedical image analysis using semantic segmentation. Journal of Innovative Image Processing (JIIP), 1(02), pp.91-101. Available at:https://irojournals.com/iroiip/V1/I2/04.pdf
Bonifati, A., Martens, W. and Timm, T., 2020. An analytical study of large SPARQL query logs. The VLDB Journal, 29(2), pp.655-679. Available at: https://link.springer.com/article/10.1007/s00778-019-00558-9
Hitzler, P., Bianchi, F., Ebrahimi, M. and Sarker, M.K., 2020. Neural-symbolic integration and the Semantic Web. Semantic Web, 11(1), pp.3-11. Available at: https://content.iospress.com/articles/semantic-web/sw190368 v
Ibrahim, R., Zeebaree, S. and Jacksi, K., 2019. Survey on Semantic Similarity Based on Document Clustering. Adv. sci. technol. eng. syst. j, 4(5), pp.115-122. Available at: https://www.researchgate.net/profile/Subhi-Zeebaree/publication/335700827_Survey_on_Semantic_Similarity_Based_on_Document_Clustering/links/5e1b708d299bf10bc3a9056a/Survey-on-Semantic-Similarity-Based-on-Document-Clustering.pdf
Lefrançois, M., Zimmermann, A. and Bakerally, N., 2017, May. A SPARQL extension for generating RDF from heterogeneous formats. In European Semantic Web Conference (pp. 35-50). Springer, Cham. Available at: https://link.springer.com/chapter/10.1007/978-3-319-58068-5_3
McCrae, J.P. and Buitelaar, P., 2018. Linking datasets using semantic textual similarity. Cybernetics and information technologies, 18(1), pp.109-123. Available at: https://sciendo.com/abstract/journals/cait/18/1/article-p109.xml
Meroño-Peñuela, A., 2017. Digital humanities on the Semantic Web: accessing historical and musical linked data. Journal of Catalan Intellectual History, 1(11), pp.144-149. Available at: http://www.journalofcatalanintellectualhistory.org/index.php/jocih/article/view/14
Pejić Bach, M., Krstić, Ž., Seljan, S. and Turulja, L., 2019. Text mining for big data analysis in financial sector: A literature review. Sustainability, 11(5), p.1277.
Reitemeyer, B. and Fill, H.G., 2019. Ontology-driven enterprise modeling: A plugin for the protégé platform. In Enterprise, Business-Process and Information Systems Modeling (pp. 212-226). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-20618-5_15
Rinaldi, A.M. and Russo, C., 2018, December. User-centered information retrieval using semantic multimedia big data. In 2018 IEEE International Conference on Big Data (Big Data) (pp. 2304-2313). IEEE. Available at: https://ieeexplore.ieee.org/abstract/document/8622613/
Satyamurty, C.V., Murthy, J.V.R. and Raghava, M., 2018. Developing higher education ontology using protégé tool: Reasoning. In Smart Computing and Informatics (pp. 233-241). Springer, Singapore. https://link.springer.com/content/pdf/10.1007/978-981-10-5544-7_24.pdf
Schekotihin, K., Rodler, P. and Schmid, W., 2018, May. Ontodebug: Interactive ontology debugging plug-in for Protégé. In International Symposium on Foundations of Information and Knowledge Systems (pp. 340-359). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-90050-6_19
Traverso, A., Van Soest, J., Wee, L. and Dekker, A., 2018. The radiation oncology ontology (ROO): Publishing linked data in radiation oncology using semantic web and ontology techniques. Medical physics, 45(10), pp.e854-e862. Available at:https://aapm.onlinelibrary.wiley.com/doi/abs/10.1002/mp.12879
Traverso, A., Van Soest, J., Wee, L. and Dekker, A., 2018. The radiation oncology ontology (ROO): Publishing linked data in radiation oncology using semantic web and ontology techniques. Medical physics, 45(10), pp.e854-e862. Available at: https://aapm.onlinelibrary.wiley.com/doi/abs/10.1002/mp.12879
Wang, L., 2017. Heterogeneous data and big data analytics. Automatic Control and Information Sciences, 3(1), pp.8-15. Available at: https://www.academia.edu/download/56056011/acis-3-1-3.pdf
White, T.D., Fraser, G. and Brown, G.J., 2019, July. Improving random GUI testing with image-based widget detection. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis (pp. 307-317). Available at: https://dl.acm.org/doi/abs/10.1145/3293882.3330551?casa_token=FUZcLNjNMRMAAAAA:yvEtG1o4kDrKH_xpWsmcN00DmpMenN2z0BaSrYpS6eo-2C7JDpYJj9J9OBSbrCJWea-Y3Pox09Nu
Wu, H., Huang, H.Y., Jian, P., Guo, Y. and Su, C., 2017, August. BIT at SemEval-2017 Task 1: Using semantic information space to evaluate semantic textual similarity. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017) (pp. 77-84). Available at: https://www.aclweb.org/anthology/S17-2007.pdf
Zeebaree, A.Z.S.R., Adel, A.Z., Jacksi, K. and Selamat, A., 2019. Designing an ontology of E-learning system for duhok polytechnic university using protégé OWL tool. J Adv Res Dyn Control Syst Vol, 11, pp.24-37. https://www.researchgate.net/profile/Adel-Al-Zebari/publication/337482636_Designing_an_Ontology_of_E-learning_system_for_Duhok_Polytechnic_University_Using_Protege_OWL_Tool/links/5ddaf85692851c1fedaf560f/Designing-an-Ontology-of-E-learning-system-for-Duhok-Polytechnic-University-Using-Protege-OWL-Tool.pdf
Zeebaree, A.Z.S.R., Adel, A.Z., Jacksi, K. and Selamat, A., 2019. Designing an ontology of E-learning system for duhok polytechnic university using protégé OWL tool. J Adv Res Dyn Control Syst Vol, 11, pp.24-37. Available at: https://www.researchgate.net/profile/Adel-Al-Zebari/publication/337482636_Designing_an_Ontology_of_E-learning_system_for_Duhok_Polytechnic_University_Using_Protege_OWL_Tool/links/5ddaf85692851c1fedaf560f/Designing-an-Ontology-of-E-learning-system-for-Duhok-Polytechnic-University-Using-Protege-OWL-Tool.pdf
Zeng, M.L. and Mayr, P., 2019. Knowledge Organization Systems (KOS) in the Semantic Web: a multi-dimensional review. International Journal on Digital Libraries, 20(3), pp.209-230. Available at: https://link.springer.com/article/10.1007/s00799-018-0241-2
Know more about UniqueSubmission’s other writing services:
