KL7011 Advanced Databases Assignment Sample
Assignment 2 – KL7011 Advanced Databases
Part 1
Question A
Data warehouses are frequently seen as business analytics platforms designed to assist a company’s day-to-day disclosure rules. They may not have the identical actual efficiency expectations as OLTP computer networks (in normal deployments), and although OLTP solutions will only hold data belonging to a limited section of the company, data warehouses aim to include all data pertaining to the company.
Data warehouse approaches provide advantages to a corporation only after the warehouse is viewed as the focal center of “all matters data,” rather than merely a tool for producing management reports (Schuetz et al. 2018). To provide data into the data warehouse and get advice about how to increase efficiency and productivity, every operational process must have 2 different connections with both the database system. Whatever economic change, including a price rise or a decrease in resource, should be developed and tested and projected inside the data warehouse system initially, such that the company can estimate and measure the consequence.
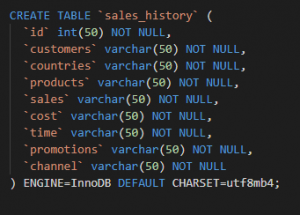 Figure 1: sql code (Source: Self-created in oracle sql developer)
Figure 1: sql code (Source: Self-created in oracle sql developer)
Data warehouses are really only relevant and profitable if the information within them is accepted by stakeholders involved. Software packages that continuously collect and repair (where feasible) data integrity concerns must be established to achieve this.

Data cleaning must be included in the data implementation phase, and periodical data inspections or data profiles should be performed to uncover any data concerns. Whereas these preventive protections are being deployed, companies should also contemplate reactive actions in the event that harmful data sneaks through these gateways and is detected either by consumers (Viloria et al. 2019). Any incorrect data flagged by corporate customers must be reviewed as a responsibility to maintain consumer trust inside the data warehouses.
Question B
In this case, here the other data set sh_cremv.sql is analyzed. Under this sql file, the SH2 shared schema has been created for materialized views. The materialized view is very important and useful for analyzing the business data and cost-based data. The sql queries for this scenario should return the subsets of the value content.
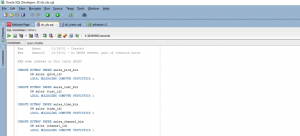 Figure 2: sql code (Source: Self-created in oracle sql developer)
Figure 2: sql code (Source: Self-created in oracle sql developer)
Schemas in Data Warehouse
The schema is a grouping of database components such as views, tables, synonyms, and indexes. In schema frameworks built for data warehousing, schema entities can be arranged in a number of methods. The following are the primary database schemas:
Star Schemas: A star schema is the most basic data warehouse design. The main sequence star is a huge fact table, while the star’s limbs are measurement tables. The star enquiry is a combination of a table structure and many linguistic variables (Costa et al. 2019).
The data fields are linked to the database via an unique identifier to foreign key connect, but they are not connected to one another. Star queries are identified by the planner and optimized order to be part is generated for it. It is not necessary for the dimension tables to contain any foreign keys for star conversion to enter into force. The star join seems to be a connection of attribute values to a table structure that uses an unique identifier to a foreign key. The primary benefits of star schemas are now that they:
- Give end customers a straightforward and understandable linkage here between commercial enterprises being studied and the schema architecture.
- For common star searches, provide greatly optimized execution.
- A vast variety of economic analytics solutions offer dimension tables that can be expected or perhaps even required by the data warehouse structure. Star schemas may be utilized for small data stores as well as very big data warehouses.
Question C
Dimensional Modeling
Dimensional modeling (DM) is a physical and logical method that aims to provide data in a consistent, user-friendly structure that enables for greater retrieval. It is fundamentally multidimensional, and it conforms to a relationship model-based approach with several significant constraints (Rogers et al. 2019).
All dimensional models are made up of one large database with such a multivolume key, known as the table structure, and a collection of different tables known as dimension (or search) tables. Every dimension table does have a separate unique identifier that matches to one of the highly detailed key elements in the dimension tables.
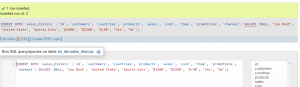 Figure 3: sql code (Source: Self-created in oracle sql developer)
Figure 3: sql code (Source: Self-created in oracle sql developer)
This distinctive “star-like” architecture is sometimes referred to as a star join. The phrase “star join” has been used from the initial periods of relational database systems. A star schema might be straightforward or complicated. A basic star has a fact table; a complicated star might have several fact tables (Ratner et al. 2019). A “snowflake-like” architecture is generated whenever one aspect is portrayed using just a hierarchical system of dimension tables.
A snowflake schema is a star schema modification in which every edge of the star bursts into additional elements. The key benefit of the snowflake structure is improved query efficiency as a result of reduced disc capacity needs and connecting fewer mathematical formulas. The biggest downside of the snowflake architecture is the increased amount of lookup tables, which necessitates more upkeep work.
Question D
In this scenario, the other two indexes are considered and analyzed using oracle sql code. In this case, the indexes are implemented under a DWU account. This analysis also depends upon the cost-based analysis (Hamoud et al. 2018). In this section, some oracle sql queries are compiled to achieve the SH2 shared scheme.
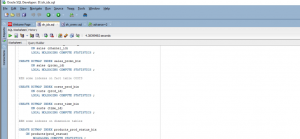 Figure 4: sql code (Source: Self-created in oracle sql developer)
Figure 4: sql code (Source: Self-created in oracle sql developer)
The fact table typically also displays several connections since it has a feature length primary key composed of two or even more foreign keys. The much more valuable fact tables also include 1 or even more reflective accounts, or “events,” that happen for every record’s collection of keys. Algebraic and cumulative facts are best valuable in a fact table.
Additively is important for data warehouse systems that usually always obtain an individual fact table entry; instead, they get thousands, hundreds, or even billions of these entries at a period, and the only practical option to be doing with many facts is add them all up (Singh et al. 2019). Dimension tables, on the other hand, are more likely to include explanatory textual data and to depict genuine physical things, events, and events. They are numerical in nature and serve as a means of organizing data.
Question E
In this case, after analyzing the “sh_idx. Sql” data set, it is answering that the queries are fully different over the SH2 and DWU version. By using these two versions of data sets, the queries are quite complicated and it can involve two different tables. In this section, the cost based analysis takes place. All the sales history of the product is also analyzed.
Part 2
Question 1
Data Analytics in Databases
In addition to individual systems, database management systems with data analytics applications are available. When approached with the problem of merging data analytics with structural ideas, the systems listed below offer a variety of answers: Requests to build – in functions are used to conduct computational approaches, or the SQL syntax is augmented with data analytics capabilities (Vieira et al. 2018). MADlib is an instance of a user-defined procedure, which is the second stage of the taxonomy.
This module runs on the highest point of chosen networks and makes extensive utilization of data parallel query processing if it is supported by the underpinning database management system. MADlib gives detailed methods in the form of user-defined procedures written in Java and Python and invoked via Sql statements. The fundamental database performs such tasks but does not have the ability to analyze or optimize them. Whereas the procedures’ result can be immediately thread with SQL, only basic relationships can be used as entry to data analytics techniques (Ali et al. 2018). As a result, however, neither the query refinement and implementation layer nor the languages and query layer accomplish complete integration of user-defined methods and SQL queries.
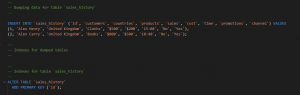 Figure 5: sql code (Source: Self-created in oracle sql developer)
Figure 5: sql code (Source: Self-created in oracle sql developer)
Oracle Data Miner is primarily concerned with guided machine learning methods. As a result, a training set is used to build a framework, which is then deployed to test data through SQL procedures. All phases are multi-threaded in order to take advantage of current multi-core platforms. The algorithms’ output is saved in relational data. It is not feasible to do proactive re-use or additional treatment of findings inside the identical Sql statement, but it is allowed to do so in previous and consecutive questions.
SimSQL is a new database system having analytical capabilities. Developers upload their own algorithms that are subsequently converted into SQL. Many SQL additions, including for type cycles over relationships and scalar and matrix types of data, make database analytics easier. SimSQL highlights its basic methodology while acknowledging that its tuple-oriented solution to matrix-based challenges leads to poor execution (Dobson et al. 2018). SimSQL is capable of performing complicated ML algorithms that many other computer systems are unable to do as a consequence of these design considerations, but it lacks improvements for typical analytical techniques. To summarize, while all of the data stores given strive towards a combination of analytics and structural queries, the amount of integration accomplished varies greatly amongst platforms.
The majority of the provided solutions rely on the application’s black box implementation of consumer procedures, although some turn complex queries into preparation suitable to provide for search examination and improvement by the system.
Question 2
Data Mining Process
The finding and recovery of connections and information from massive data sets of organized and unorganized data is referred to as data mining. Although data mining approaches have indeed been present for several generations, recent developments in ML (Machine Learning), processing ability, and quantitative computing have made information mining approaches simpler to employ on massive information sets and in business-related activities (Viloria et al. 2019).
The development of Cloud Computing and Cloud Services is also contributing to the increasing importance of data analysis in corporate statistics and advertising. Distributed network networks and concurrent information processing algorithms, like Map Reduce, make massive amounts of data accessible and beneficial for businesses and research. Moreover, cloud service providers (CSPs) that offer a compensation strategy to use simulated computers, storage capabilities (hard drive), GPUs (Graphical Processing Units), and data warehouses minimize the price of data storage. Like a consequence, businesses may collect, analyze, and analyze additional data, resulting in more accurate advanced analytics.
- After analyzing all the data of this sh_cremv.sql data set, the MVs based table for the SH schema is placed under the data warehouse. In this section, the oracle sql code is used to develop these MVs.
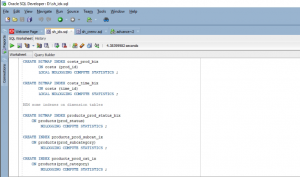 Figure 6: sql code (Source: Self-created in oracle sql developer)
Figure 6: sql code (Source: Self-created in oracle sql developer)
Question 3
In this section, the data set of global credit finance is being analyzed (Islam et al. 2018). In the Global CRF case scenario, the clustering and regression model of the data mining process is very appropriate. In the clustering process, data and information are clustered and added in the data mining section. Also, regression is used to analyze the data set. The predictive data mining model is very suitable and appropriate for this Global CRF scenario.
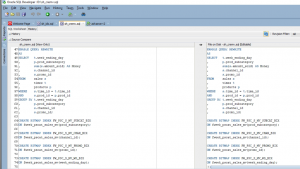 Figure 7: sql code (Source: Self-created in oracle sql developer)
Figure 7: sql code (Source: Self-created in oracle sql developer)
Descriptive analysis
Descriptive analytics is just a sort of data processing wherein the previously collected data is gathered, analyzed, and then shown in an intelligible way. Descriptive analytics mainly focuses on what really happened in a company and, unlike some other research methods, does not use its findings to create judgments or projections.
Descriptive analytics, on the other hand, is a good place to start since it employs interpreting or arranging data for further analysis. To identify historical information, descriptive analytics employs two different processes: data gathering and data mining (often called data retrieval). The act of obtaining this information to form digestible sets of data is known as data aggregate. Those sets of data are then utilized in the data gathering phase to recognize trends, patterns, and significance, which is then displayed in an intelligible manner.
Question 4
Predictive data analysis
While descriptive analytics is concerned with historical data, business intelligence, even as name implies, is engaged with forecasting and analyzing whatever may happen in the future. Analyzing prior data trends and patterns utilizing historical data and market knowledge helps foresee what will occur in the future and so affects many aspects of a company, like defining project goals, appropriate planning, regulating performance targets, and limiting risk.
Assumptions are the foundation of data analytics (Sugiyarti et al. 2018). Data analysis makes an attempt to anticipate future probable new consequences and the possibility of such occurrences by using a variety of methods like data mining, data techniques (arithmetical correlation coefficients to anticipate results), and machine learning algorithms (designation, regression, and clustering techniques). Machine learning algorithms, for instance, utilize current information and try to replace the incomplete information with the best available estimates to produce forecasts.
Question 5
Data Analytics in the Database Core
In comparison to many other database management systems, HyPer incorporates critical data analytics capability right into the database program’s base by incorporating specially optimized processors for analyzing techniques. Since the underlying architecture of data stores varies so greatly, similar functions must be developed and executed especially for every platform. The implementation paradigm (tuple-at-a-time vs. vectorized operation) and memory type, for example, are important differentiators across systems (row store vs. column store).
A controller in the analytical machine Tupperware, for instance, might appear very distinct from an operation in the packed database management HyPer that must handle changes and search separation. HyPer allows users to freely blend relationships and analytical technicians, resulting in a tight connectivity of analytics as well as other SQL expressions into a single given process (Tute et al. 2018). This is particularly beneficial since traditional relational processors’ functionality may be utilized for typical sub – tasks in analyzing methods, including such combining or filtering.
Analytical operators might concentrate on improving the fundamental concept of the algorithm by delivering effective external representations of data, executing algorithm dependent pre-processing procedures, and accelerating integer arithmetic loops. Another benefit of custom-built analytic operations would be that the query processor is aware of their specific attributes and may select the best query program based on this knowledge (Ptiček et al. 2018).
Combining all pre- and post-processing stages inside one language—and one query—simplifies data analytics and enables for quick ad hoc inquiries. It expands on existing (actual) operator design. Special operations forces are the most thoroughly incorporated into the database of the connection layers mentioned in this area.
As a consequence, they offer unequaled efficiency while limiting the user’s freedom. Designers suggest lambda variables as a method of inserting viewer code into operations to recover versatility. Lambdas could be used to establish empirical formulas in the k-Means method or to determine a set of weights in PageRank, for instance.
Part 3
Data Security Solutions for Data Warehousing
Preventive Data Security Solutions
Preventive data security techniques, like trying to implement traceability and multithreaded restrictions, shared data guidelines, data masking and data encryption for modifying actual data principles, and hash functions for integrity verification on started changing information, are used to protect information that is crucial for attacks. Modern Database Systems (DBMS) provide for the definition of relational model requirements, input validation criteria, position authorization rules, and ACID compliance, that all ensure consistency of data, accuracy, and secrecy to a degree.
Checksum algorithms have long been seen in DBMS to verify stored information for errors and identify data malfeasance. As stated in, one method for identifying authentic data from altered data is to use signature in all DW entries. CRC, MD5, and SHA techniques are another method for identifying integrity problems. Data masking is a simple method of preventing data exposure by directly adjusting and substituting actual data contents.
Oracle, for example, describes current best practices for encrypting data in their DBMS in detail. Encryption is a sophisticated kind of data masking that is extensively employed to enforce data security. Oracle created TDE (Transparent Data Encryption) in their DBMS editions 10g and 11g, combining some well conventional encryption methods AES and 3DES. Oracle 11g TDE encrypts data by employing a set of primary and secondary keys that may be used for row and originally formulated encryption. These approaches are clean, needing no changes to the user’s code base. If the database’s filesystem is taken or duplicated without permission, no data will be shown properly because its information is all protected.
Reactive Data Security Solutions
The basic purpose of Intrusion Detection Systems (IDS) is to identify unauthorized access, which is composed of two fundamental concepts: abuse identification, which looks for pathway activation well-known assaults, and outlier detection, which looks for departures from everyday activities. Statistical techniques or predicting that it is vital may be used to discover anomalies. The majority of detecting attacks is focused on recognizing predetermined intrusion attempts. Data Mining (DM) is employed in both strategies to minimize human labor while increasing detection performance. Database DM-based intrusion detection systems (IDS) have been recently developed. IDS also include the supervision of user inquiries.
Techniques for coping with SQL injection are presented in text mining and/or computer vision. The most important responsibilities in DW available data are major correction of faulty or wrongly updated data and uninterrupted 24/7 access permissions. Most systems address these challenges by duplicating data so that lost data may be recovered at any time, allowing periodic intervention to reduce database unavailability, and dividing query execution attempts to avoid connectivity hotspot.
On systems with centralized servers, one technological solution for duplicating data is the use of well-known RAID topologies. Nevertheless, in order to save costs, an increasing number of businesses are putting their DWs on low-cost commodity PCs, which often have just one disc drive and do not support RAID architecture. Appropriate commercial systems for addressing document challenges in DWs, like Oracle RAC or Aster Data, are now commercially available. Another method for rectifying faulty data is to use error checking codes like Pepping codes.
Computer storage methods capable of recovering from block size damage, like employing error corrective codes, mirroring, and reprogramming of faulty blocks, have indeed been suggested. Many systems make use of these capabilities and supplement them with security approaches for spreading storage. Thorough investigation and self-healing system designs have been developed. Considering the amount of server and storage space normally associated, distributed database strategies are always a key concern in DWs, while being very successful for reliability objectives.
Reference List
Journal
Islam, M.S., Hasan, M.M., Wang, X. and Germack, H.D., 2018, June. A systematic review on healthcare analytics: application and theoretical perspective of data mining. In Healthcare (Vol. 6, No. 2, p. 54). Multidisciplinary Digital Publishing Institute.
Schuetz, C.G., Schausberger, S. and Schrefl, M., 2018. Building an active semantic data warehouse for precision dairy farming. Journal of Organizational Computing and Electronic Commerce, 28(2), pp.122-141.
Sugiyarti, E., Jasmi, K.A., Basiron, B., Huda, M., Shankar, K. and Maseleno, A., 2018. Decision support system of scholarship grantee selection using data mining. International Journal of Pure and Applied Mathematics, 119(15), pp.2239-2249.
Viloria, A., Acuña, G.C., Franco, D.J.A., Hernández-Palma, H., Fuentes, J.P. and Rambal, E.P., 2019. Integration of data mining techniques to PostgreSQL database manager system. Procedia Computer Science, 155, pp.575-580.
Viloria, A., Rodado, D.N. and Lezama, O.B.P., 2019. Recovery of scientific data using intelligent distributed data warehouse. Procedia Computer Science, 151, pp.1249-1254.
Costa, E., Costa, C. and Santos, M.Y., 2019. Evaluating partitioning and bucketing strategies for Hive-based Big Data Warehousing systems. Journal of Big Data, 6(1), p.34.
Rogers, W.P., Kahraman, M.M. and Dessureault, S., 2019. Exploring the value of using data: a case study of continuous improvement through data warehousing. International Journal of Mining, Reclamation and Environment, 33(4), pp.286-296.
Ratner, H. and Gad, C., 2019. Data warehousing organization: Infrastructural experimentation with educational governance. Organization, 26(4), pp.537-552.
Vieira, A.A., Pedro, L., Santos, M.Y., Fernandes, J.M. and Dias, L.S., 2018, October. Data requirements elicitation in big data warehousing. In European, Mediterranean, and Middle Eastern Conference on Information Systems (pp. 106-113). Springer, Cham.
Singh, M.P., Sural, S., Vaidya, J. and Atluri, V., 2019. Managing attribute-based access control policies in a unified framework using data warehousing and in-memory database. Computers & security, 86, pp.183-205.
Ali, A.R., 2018, March. Real-time big data warehousing and analysis framework. In 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA) (pp. 43-49). IEEE.
Dobson, S., Golfarelli, M., Graziani, S. and Rizzi, S., 2018. A reference architecture and model for sensor data warehousing. IEEE Sensors Journal, 18(18), pp.7659-7670.
Ptiček, M. and Vrdoljak, B., 2018, May. Semantic web technologies and big data warehousing. In 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO) (pp. 1214-1219). IEEE.
Moly, M., Roy, O. and Hossain, A., 2019. An advanced ETL technique for error-free data in data warehousing environment. Int. J. Sci. Res. Eng. Trends, pp.554-558.
Tute, E. and Steiner, J., 2018. Modeling of ETL-Processes and Processed Information in Clinical Data Warehousing. eHealth, pp.204-211.
Vicuna, P., Mudigonda, S., Kamga, C., Mouskos, K. and Ukegbu, C., 2019. A generic and flexible geospatial data warehousing and analysis framework for transportation performance measurement in smart connected cities. Procedia Computer Science, 155, pp.226-233.
Know more about UniqueSubmission’s other writing services:
