Statistics Assignment for Business Decisions
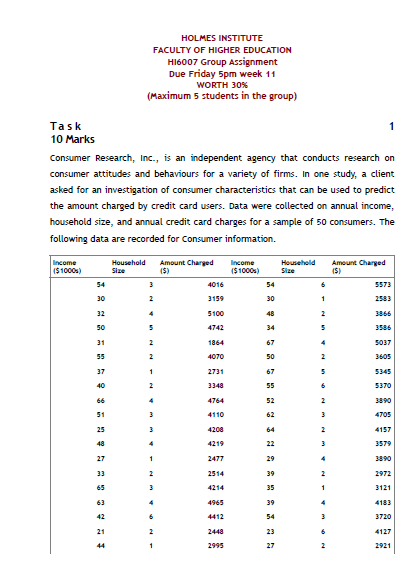
The below tables show the descriptive statistics for all variables:
| Income
|
|
| Mean | 43.48 |
| Standard Error | 2.057785614 |
| Median | 42 |
| Mode | 54 |
| Standard Deviation | 14.55074162 |
| Sample Variance | 211.7240816 |
| Kurtosis | -1.247719422 |
| Skewness | 0.095855639 |
| Range | 46 |
| Minimum | 21 |
| Maximum | 67 |
| Sum | 2174 |
| Count | 50 |
Household Size:
| Household Size
|
|
| Mean | 3.42 |
| Standard Error | 0.245930138 |
| Median | 3 |
| Mode | 2 |
| Standard Deviation | 1.738988681 |
| Sample Variance | 3.024081633 |
| Kurtosis | -0.722808552 |
| Skewness | 0.527895977 |
| Range | 6 |
| Minimum | 1 |
| Maximum | 7 |
| Sum | 171 |
| Count | 50 |
Amount Charged:
| Amount Charged
|
|
| Mean | 3963.86 |
| Standard Error | 132.023387 |
| Median | 4090 |
| Mode | 3890 |
| Standard Deviation | 933.5463219 |
| Sample Variance | 871508.7351 |
| Kurtosis | -0.742482171 |
| Skewness | -0.128860064 |
| Range | 3814 |
| Minimum | 1864 |
| Maximum | 5678 |
| Sum | 198193 |
| Count | 50 |
Interpretation:

Based on descriptive statistics, average income level of the consumers is approx $43480, whereas average household size is between 3 and 4. In addition, average amount charged to the consumers is approx $3964 by the credit card users. Household size of sample is between 1 and 7.
At the same time, coefficient of variance is very high for income and amount charged by credit card users. In addition, values of kurtosis and skewness near to ±1 indicate consistency of the data distribution closed to the average of the data for each variable. The data for all variables shows acceptability for empirical use.
At the same time, correlation between variable can be determined as below:
| Variables | Correlation |
| Income-household size | 17.25% |
| Income-Amount charged | 63.08% |
| Amount charged-household size | 75.28% |
Above statistics show that there is a significant correlation between income & amount charged and household size & amount charged by credit card users.
2. Estimated regression equations
Annual income and credit card charges:
| SUMMARY OUTPUT | ||||||||
| Regression Statistics | ||||||||
| Multiple R | 0.630780826 | |||||||
| R Square | 0.39788445 | |||||||
| Adjusted R Square | 0.385340376 | |||||||
| Standard Error | 731.902474 | |||||||
| Observations | 50 | |||||||
| ANOVA | ||||||||
| df | SS | MS | F | Significance F | ||||
| Regression | 1 | 16991228.91 | 16991228.91 | 31.71891773 | 9.10311E-07 | |||
| Residual | 48 | 25712699.11 | 535681.2315 | |||||
| Total | 49 | 42703928.02 | ||||||
| Coefficients | Standard Error | t Stat | P-value | Lower 95% | Upper 95% | Lower 95.0% | Upper 95.0% | |
| Intercept | 2204.240517 | 329.1340306 | 6.697090887 | 2.14344E-08 | 1542.472207 | 2866.009 | 1542.472 | 2866.009 |
| X Variable 1 | 40.46962932 | 7.185715961 | 5.631955054 | 9.10311E-07 | 26.02177931 | 54.91748 | 26.02178 | 54.91748 |
Regression equation:
y= mx+ c
y= 40.4696x + 2204.24
Here,
x = Annual income
y = Annual credit card charges
Household size and credit card charges:
| SUMMARY OUTPUT | ||||||||
| Regression Statistics | ||||||||
| Multiple R | 0.752853835 | |||||||
| R Square | 0.566788897 | |||||||
| Adjusted R Square | 0.557763666 | |||||||
| Standard Error | 620.8162594 | |||||||
| Observations | 50 | |||||||
| ANOVA | ||||||||
| df | SS | MS | F | Significance F | ||||
| Regression | 1 | 24204112.28 | 24204112.28 | 62.80048437 | 2.86236E-10 | |||
| Residual | 48 | 18499815.74 | 385412.8279 | |||||
| Total | 49 | 42703928.02 | ||||||
| Coefficients | Standard Error | t Stat | P-value | Lower 95% | Upper 95% | Lower 95.0% | Upper 95.0% | |
| Intercept | 2581.644082 | 195.269886 | 13.22090228 | 1.287E-17 | 2189.027669 | 2974.26 | 2189.028 | 2974.26 |
| X Variable 1 | 404.1567013 | 50.99977822 | 7.924675664 | 2.86236E-10 | 301.6147764 | 506.6986 | 301.6148 | 506.6986 |
Regression equation:
y= mx+ c
y= 404.156X + 2581.64
Here,
x = Household Size
y = Annual credit card charges
Regression analysis for both variables indicates that household size variable is better predictor of annual credit card charges as compared to income. It is because R2 for variable income is 0.3978 means approx 40% of the variation in amount charged can be explained by annual income.
Meanwhile, On the other hand, R2 for household size variable is approx 0.57 implies about 57% of the variation in amount charged can be explained by household size.
3. Estimated regression equations
| SUMMARY OUTPUT | ||||||||
| Regression Statistics | ||||||||
| Multiple R | 0.908501824 | |||||||
| R Square | 0.825375565 | |||||||
| Adjusted R Square | 0.817944738 | |||||||
| Standard Error | 398.3249315 | |||||||
| Observations | 50 | |||||||
| ANOVA | ||||||||
| df | SS | MS | F | Significance F | ||||
| Regression | 2 | 35246778.72 | 17623389.36 | 111.0745228 | 1.54692E-18 | |||
| Residual | 47 | 7457149.298 | 158662.751 | |||||
| Total | 49 | 42703928.02 | ||||||
| Coefficients | Standard Error | t Stat | P-value | Lower 95% | Upper 95% | Lower 95.0% | Upper 95.0% | |
| Intercept | 1305.033885 | 197.770988 | 6.598712469 | 3.32392E-08 | 907.1699825 | 1702.898 | 907.17 | 1702.898 |
| X Variable 1 | 33.12195539 | 3.970237444 | 8.342562845 | 7.88598E-11 | 25.13486801 | 41.10904 | 25.13487 | 41.10904 |
| X Variable 2 | 356.3402032 | 33.22039979 | 10.72654771 | 3.17247E-14 | 289.5093801 | 423.171 | 289.5094 | 423.171 |
y=m1x1 + m2x2 + c
y= 33.12 x1 + 356.34 x2 + 1305.03
Where,
y= Amount Charged
x1 = Income
x2 = Household Size
The above regression analysis shows that R2 is 0.8253 indicating household size and income can explain about 82.53% of the variation in amount charged. From this, it can be determined that both variables together have low significance in comparison of the single variables. Standard error for both variables together is less than the single variables indicating improvement in regression model.
4. Predicted annual credit card charge
y=m1x1 + m2x2 + c
y= 33.12 x1 + 356.34 x2 + 1305.03
y= 33.12 *40 + 356.34 *3 + 1305.03
y= 1324.8 + 1069.02 + 1305.03
y= $3698.85
The predicted annual credit card charge for a three-person household with an annual income of $40,000 is approx $3,699.
5. Other independent variables
Number of credit card could be added to the model as independent variable to determine its relationship with amount charged by credit card users. There may be a significant relationship between multiple cards and amount charged. Age and gender of the consumers can also be significant in determining amount charged.
It is because youngsters and female consumers are likely to purchase more as it can increase the amount charged by credit card users. In addition, purchasing options including online and offline modes can be considered to determine buying patterns of customers.
| Descriptive Stats | HI001 FINAL EXAM | HI001 ASSIGNMENT 01 | HI001 ASSIGNMENT 02 |
| Mean | 31.72 | 17.21 | 15.46 |
| SD | 6.75 | 1.99 | 2.31 |
| Min | 0 | 8 | 8 |
| Max | 45 | 22 | 21 |
| Descriptive Stats | HI002 FINAL EXAM | HI002 ASSIGNMENT 01 | HI002 ASSIGNMENT 02 |
| Mean | 26.50 | 17.82 | 12.42 |
| SD | 5.91 | 3.44 | 1.99 |
| Min | 0 | 4 | 4 |
| Max | 40 | 22 | 16 |
| Descriptive Stats | HI003 FINAL EXAM | HI003 ASSIGNMENT 01 | HI003 ASSIGNMENT 02 |
| Mean | 25.99 | 18.19 | 13.54 |
| SD | 8.27 | 3.91 | 1.76 |
| Min | 4 | 10 | 8 |
| Max | 43 | 30 | 20 |
| Variables | Correlation |
| HI001 FINAL EXAM- HI001 ASSIGNMENT 01 | 9.26% |
| HI001 ASSIGNMENT 02- HI001 ASSIGNMENT 01 | 65.94% |
| HI002 FINAL EXAM- HI001 ASSIGNMENT 02 | -3.74% |
| HI002 ASSIGNMENT 02- HI002 ASSIGNMENT 01 | 54.90% |
| HI003 ASSIGNMENT 02- HI003 ASSIGNMENT 01 | 51.98% |
| HI002 ASSIGNMENT 02- HI002 FINAL EXAM | 36.26% |
| HI003 FINAL EXAM- HI002 ASSIGNMENT 01 | 1.55% |
| HI003 ASSIGNMENT 01- HI002 FINAL EXAM | -6.00% |
| HI003 FINAL EXAM- HI001 ASSIGNMENT 01 | 23.17% |
| HI001 FINAL EXAM- HI003 FINAL EXAM | 12.19% |
| HI002 FINAL EXAM- HI001 FINAL EXAM | 4.92% |
| Variables | Correlation | Positive/Negative | Strong/Weak | Significance value |
| HI001 FINAL EXAM- HI001 ASSIGNMENT 01 | 9.26% | Positive | Weak | Not significant |
| HI001 ASSIGNMENT 02- HI001 ASSIGNMENT 01 | 65.94% | Positive | Strong | significant |
| HI002 FINAL EXAM- HI001 ASSIGNMENT 02 | -3.74% | Negative | Weak | Not significant |
| HI002 ASSIGNMENT 02- HI002 ASSIGNMENT 01 | 54.90% | Positive | Strong | significant |
| HI003 ASSIGNMENT 02- HI003 ASSIGNMENT 01 | 51.98% | Positive | Strong | significant |
| HI002 ASSIGNMENT 02- HI002 FINAL EXAM | 36.26% | Positive | Weak | Not significant |
| HI003 FINAL EXAM- HI002 ASSIGNMENT 01 | 1.55% | Positive | Weak | Not significant |
| HI003 ASSIGNMENT 01- HI002 FINAL EXAM | -6.00% | Negative | Weak | Not significant |
| HI003 FINAL EXAM- HI001 ASSIGNMENT 01 | 23.17% | Positive | Weak | Not significant |
| HI001 FINAL EXAM- HI003 FINAL EXAM | 12.19% | Positive | Weak | Not significant |
| HI002 FINAL EXAM- HI001 FINAL EXAM | 4.92% | Positive | Weak | Not significant |
In the above table, significance value reveals that HI001 ASSIGNMENT 02- HI001 ASSIGNMENT 01, HI002 ASSIGNMENT 02- HI002 ASSIGNMENT 01 and HI003 ASSIGNMENT 02- HI003 ASSIGNMENT 01 have strong correlation to each other.
It means the students who received good marks in HI001 ASSIGNMENT 01, also achieved similar marks in HI001 ASSIGNMENT 02. This pattern is also followed in next assignments as well.
|
Medical Study 1 |
||||
| Groups | Count | Sum | Average | Variance |
| Florida | 20 | 111 | 5.55 | 4.576316 |
| New York | 20 | 160 | 8 | 4.842105 |
| North Carolina | 20 | 141 | 7.05 | 8.05 |
| Medical Study 2 | ||||
| Groups | Count | Sum | Average | Variance |
| Florida | 20 | 290 | 14.5 | 10.05263 |
| New York | 20 | 305 | 15.25 | 17.03947 |
| North Carolina | 20 | 279 | 13.95 | 8.681579 |
From the above descriptive statistics, it can be interpreted that there is higher depression among normal individuals in New York in comparison of Florida and North Carolina.
In addition, individuals with a chronic health condition such as arthritis, hypertension, and/or heart ailment have similar depression level but high in all locations. But, people with chronic disease have higher depression in comparison of normal individuals.
Study 1:
Hypothesis Formulation:
H0: µ1=µ2=µ3
No difference in the mean depression score of healthy people in all three locations.
Ha: µ1≠µ2≠µ3 significant difference in the mean depression score of healthy people in all three locations.
Where,
µ1= the mean depression score of healthy people in Florida
µ2= the mean depression score of healthy people in New York
µ3= the mean depression score of healthy people in North Carolina
Rejection Rule: The null hypothesis is rejected if, p-value ≤0.05)
ANOVA Single Factor:
| ANOVA | ||||||
| Source of Variation | SS | df | MS | F | P-value | F crit |
| Between Groups | 61.03333 | 2 | 30.51666667 | 5.240886 | 0.00814 | 3.158842719 |
| Within Groups | 331.9 | 57 | 5.822807018 | |||
| Total | 392.9333 | 59 |
Interpretation:
Here, p value is less 0.05, so the null hypothesis is rejected. Therefore, the mean depression score of healthy people is significantly different in the three locations.
Study 2:
ANOVA Single Factor:
| ANOVA | ||||||
| Source of Variation | SS | df | MS | F | P-value | F crit |
| Between Groups | 17.03333333 | 2 | 8.516667 | 0.714212 | 0.493906 | 3.158843 |
| Within Groups | 679.7 | 57 | 11.92456 | |||
| Total | 696.7333333 | 59 |
Interpretation:
Here, p value is greater than 0.05 as the null hypothesis is accepted. The mean depression score of individuals with a chronic health condition is not significantly different in the three locations.
Based on the above analysis, it can be concluded that in test 1, the mean depression score related to locations because there are differences in score in each location. Individuals in New York possess high depression score as compared to other locations.
The mean depression score of individuals with chronic disease does not relate with locations as there is similarity in these scores for all locations.
Berenson, M., Levine, D., Szabat, K. A., & Krehbiel, T. C. (2012) Basic business statistics: Concepts and applications. Australia: Pearson higher education AU.
Heiko, A. (2012) Consensus measurement in Delphi studies: review and implications for future quality assurance. Technological forecasting and social change, 79(8), pp. 1525-1536.
Newbold, P., Carlson, W., & Thorne, B. (2012) Statistics for business and economics. UK: Pearson.
Siegel, A. (2016) Practical business statistics. UK: Academic Press.
