
WEB-BASED INTERACTIVE DATA VISUALISATION
Consuming a large data set is not a straight forward method always. As the set of data are larger than the other data, it becomes impossible to get something useful from the data sets. Creating the visualization of the data is tough and it is quite straight forward.
The designers can select a simple set of data with a numerous for example thousand entries, and with the help of the entries we can create a visualization technique. But we should think whether it is possible to spend so much of hours in plotting the chart or the diagram. So, the solution for this problem is the usage of visualization tools.

The visualization data tools offers the designers a set of data to create an easy way of representing the large number of data sets in a visual format.
When there is a large number of data set like hundreds or even thousand or the data points more than a million then the process of automating called visualization creation or the creating of visualization comes in which makes the work easier for the designers.
These types of the data visualizations is used widely for a various of purposes like annual reports, sales, dash boards, materials of marketing slide decks, and is used anywhere it is needed. These informations we are using for the set of data should be interpreted as soon as possible.
When comparing it with the annual report which is prepared for every year for every class and for each person. Then the data set will become large and it is impossible to handle. So creating a visualization offers the visual for each data set and can be saved easily.
The data visualization is a tool which is in the market and have a common things along with the data set. The first pros of the visualization of the data set is it is very easy to use, and any one ca use it. There are some friendly user applications which is available exclusively for the data visualization. Some of the data visualization has documentation and tutorials which are excellent and is designed to feel easy for the users and the customers.

Fig 1: Gender Mind Map
The best data visualization tools can easily handle the numerous data set, and it is best method that it can handle even multiple data and the sets in a single type visualization. The best data tools can also provide an offer for the array of various graph, map, chart, and many other types. The tools mentioned are mostly can output both the interactive graphs and the images.
There are some other exceptions in the criteria output. The tools of data visualization mainly focuses on a particular chart type or picture, even focuses on map. These types are referred to as the best tools in the process.
When we consider the cost, it does not require a maximum price tag for disqualifying a data tool, it should be justified in particular terms like features, support, and the value of overall process should be better.
VISUALIZATION
Visualization is said to be as the representation of the data and information like the visual element graphs, pie charts, maps pictures etc. The visualization is defined with different definition all over the country.

Fig 2: Data Visualization

Fig: status comparison

Module completion status
There are numerous of the data, tools, applications and various java scripts are available online in order to overcome the disadvantage of the data visualization. The normal visualization techniques are not having the capability or not it is easier to use.
TABLEAU
The Tableau has a lot of options which is available online includes the application of the desktop, the host, and the server which is available in many versions, and consists of free opinion of public. There are numerous imported data sets and the CSV files for the data analytics of salesforce information and the google Ads. The output of the options includes a different types of the charts and their formats as well as the capability of mapping. That is the designers has the ease of creating the color coded type maps and the geographical showcase that is important to format always.
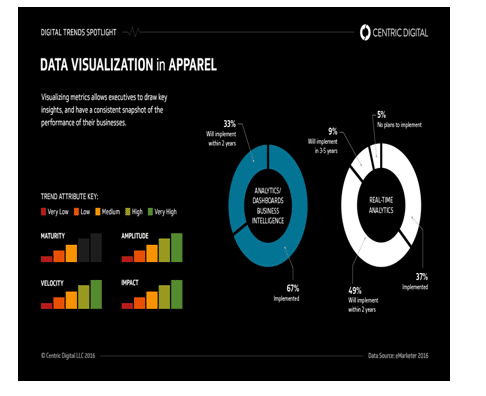
Fig 3: Data Visualization Driving Result
ADVANTAGES
- Data import options are numerous
- Capability of mapping
- Free availability of public version
- Lots of tutorials are available online for explaining how to use Tableau
DISADVANTAGES
- Non-free versions are Very costly that is $70 per month and for single user for the Creator of software. The public version will not allow us to keep data analyses in private.
Mind maps are the information’s which are represented graphically. In contrast, the visualization traditional technique allow us to take linear notes in the document or the text document, these mind maps allow us to capture some of our unique thoughts, keywords and the ideas, and we can organize the data sets into the structure of two dimension.
The main motive of the mind map is to locate the map at the center and it should be always clear. Mind maps can easily store and can easily retrieve enormous information’s. They are hierarchy in its structure and also show the relationship in between the ideas of each individual person, and can see a big picture at a single glance.

Fig 4: Mind Map for Project Managers
Average attendance for each module
Using the data visualization which is web based we can easily take the average attendance of the students in a college or university can be easily stored even if it is hundreds and more data.
Overall average attendance for the semester
Each student attendance is monitored along with the overall student attendance in a particular semester and it is created using the web data visualization.
Time of day
Each date and the time of creation of the data visualization is to be monitored and to have a note so that the data sets will be in a copy always.
Day of the week
The attendance software is to be created for a particular day and the whole week of the students and the data set can be stored easily.
Point in the semester
The semester number and the year of the semester in which the student attendance is noted has to be made visual for easy retrieval. In each semester each student attendance is to be maintained either in hand notes or in the system. Then it can be converted using the tools of data visualization and can be viewed anytime visually.
Gender
The gender of the student should be noted compulsorily during the marking of attendance and the data set should be visually stored.
Evaluation of mark
Individual mark of member is calculated using,
Member = Project mark * (Total subject/ Total members) = %
Peer Assessment Factor = (individual total weight) / 13
The data visualization is developed using the Java script coding and it provides a better understanding how data visualization and its tool works with the developed coding.
The above coding represents the web based client program of the data visualization in which it has a four plane UI browser which provides the mini type map at the top corner left, and a zoom part in the right corner bottom. The control path flow execution of coding is visualized.
CODING
import pandas as pd df = pd.read_csv(‘students_results.csv’)
varyScale = d3.scaleLinear().domain([0, d3.max(dataset, function(d) { return d[1]; })]).range([0, h]);
.attr(“cx”, function(d) {return d[0];
df.shape
(88884, 95)
df.head()df[‘status’].value_counts()P 4938NULL 3133Name: Pass, dtype: int64df[‘status’].value_counts(pass=True)df[‘studentid’].value_counts(normalize=True)%matplotlib inlinedf[‘status’].value_counts().plot(kind=”pass”)<matplotlib.axes._subplots.AxesSubplot at 0x2142658a9b0>df[‘status’].value_counts().plot(kind=”pass”, figsize=(15,7), color=”#61d199″)said_no = df[df[‘ststus’] == ‘No’]said_no.head(3)varyAxis = d3.axisLeft().scale(yScale).ticks(5);svg.append(“g”) .attr(“class”, “axis”) .attr(“transform”, “translate(” + padding + “,0)”) .call(yAxis);var dataset = [];varnumDataPoints = 50;var xRange = Math.random() * 1000;var yRange = Math.random() * 1000;for (var i = 0; i <numDataPoints; i++) {var newNumber1 = Math.floor(Math.random() * xRange);var newNumber2 = Math.floor(Math.random() * yRange); dataset.push([newNumber1, newNumber2])svg.selectAll(“text”) .data(dataset) .text(function(d) {return d; }) .attr(“x”, function(d, i) {return xScale(i) + xScale.bandwidth() / 2; }) .attr(“y”, function(d) {return h – yScale(d) + 14;print(filtered_1[‘status’].value_counts())print(filtered_1[‘pass’].value_counts())exec
OUTPUT
| Member name | Individual Weighting Factor |
| Member 1 | 60% |
| Member 2 | 75% |
| Member 3 | 58% |
| Member 4 | 73% |
| Member 5 | 56% |
| Member 6 | 91% |
| Member 7 | 66% |
| Member 8 | 8% |
| Member 9 | 74% |
| Member 10 | 70% |
| Member 11 | 83% |
| Member 12 | 90% |
| Member 13 | 50% |
| Total | 71% |

Fig 5: Over all student percentage

Fig 6: Comparison chart between boys and girls
DISCUSSION
In this research we have discussed about handling the large and enormous number of high data sets are being monitored and managed with the help of the creation of visualization.
The researchers now have realized that the applying of the technologies of visualization has some limitations on various data sets and it should be solve itself.
The data visualization plays a pivotal role in defining the problem of the large data volume and the various variety of the data set and the value of the data set. It also defines how the large data set like attendance of the students in a college or university is managed using the tools of data visualization.
A new sight is provided based on the data set using the data visualization tools. This research mainly focused about the tools of the data visualization and the analytical system that is to be handled.
The techniques of visualization are heterogeneous networks and the single attributes. This research provides a huge contribution to the visualization of the data and mainly focusing on the current data topic. We can further extend this research of analysis and processing the data visualization.
REFERENCES
- Wang, J. Liu, S. Yu, C. Zhang, Z. Xu, and F. Xia, ‘‘Mining advisor- advisee relationships in scholarly big data: A deep learning approach,’’ in Proc. IEEE/ACM Joint Conf. Digit. Libraries (JCDL), Jun. 2016, pp. 209–210.
- E. M. Barak and J. S. Brekke, ‘‘Social work science and identity formation for doctoral scholars within intellectual communities,’’ Res. Social Work Pract., vol. 24, no. 5, pp. 616–624,2014.
- Cormode, S. Muthukrishnan, and J. Yan, ‘‘People like us: Mining scholarly data for comparable researchers,’’ in Proc. 23rd Int. Conf.World Wide Web, 2014, pp.1227–1232.
- D. Hansen and C. R. Johnson, Visualization Handbook. Orlando, FL, USA: Academic, 2011.
- L. Naps et al., ‘‘Exploring the role of visualization and engagement in computer science education,’’ ACM SIGCSE Bull., vol. 35, no. 2, pp. 131–152, 2002.
- Xia, X. Su, W. Wang, C. Zhang, Z. Ning, and I. Lee, ‘‘Bibliographic analysis of nature based on twitter and Facebook altmetricsdata,’’ PLoS ONE, vol. 11, no. 12, p. e0165997,2016.
- H. McCormick, T. A. DeFanti, and M. D. Brown, ‘‘Visualization in scientific computing,’’ Computer. Graphics, vol. 21, no. 6, p. 69,1987.
- A. Keim, ‘‘Information visualization and visual data mining,’’ IEEE Trans. Vis. Computer. Graphics, vol. 8, no. 1, pp. 1–8, Jan.2002.
- L. Fung and K.-L. Ma, ‘‘Visual characterization of personal biblio- graphic data using a botanical tree design,’’ in Proc. IEEE VIS Workshop Pers. Vis., Exploring Data Everyday Life, 2015, pp.1–4.
R.P.Light,D.E.Polley,andK.Börner,‘‘Opendataandopencodeforbig scienceofsciencestudies,’’Scientometrics,vol.101,no.2,pp.1535–1551, 2014.
- Lee, F. Xia, and G. Roos, ‘‘Aobservation of research complexity in top universitiesbasedonresearchpublications,’’inProc.26thInt.Conf.World Wide Web Companion, 2017, pp.1259–1265.
- Keim, J. Kohlhammer, G. Ellis, and F. Mansmann, Eds., Mastering the Information Age Solving Problems withVisual Analytics. Goslar, Ger- many: Eurographics Association,2010.
- Bai, J. Hou, H. Du, X. Kong, and F. Xia, ‘‘Evaluating the impact of articles with geographical distances between institutions,’’ in Proc. 26th Int. Conf. World Wide Web Companion, 2017, pp.1243–1244.
- Li, C. Liu, L. Chen, Z. He, A. Datta, and F. Xia, ‘‘topic: Influential topic discovery from information networks via keyword query,’’ in Proc. 26th Int. Conf. World Wide Web Companion, 2017, pp. 231–235.
- Chen, ‘‘Visualizing semantic spaces and author co-citation networks in digitallibraries,’’Inf.Process.Manage.vol.35,no.3,pp.401–420,1999.
- Wang, J.Liu,F.Xia,I.King,andH.Tong,‘‘Shifu:Deeplearningbased advisor-advisee relationship mining in scholarly big data,’’ in Proc. 26th Int. Conf. World Wide Web Companion, 2017, pp.303–310.
- Chen, ‘‘CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature,’’ J. Amer. Soc. Inf. Sci. Technol., vol. 57, no. 3, pp. 359–377,2006.
- Sinha et al., ‘‘anoverview of Microsoft academic service (MAS) and applications,’’inProc.24thInt.Conf.WorldWideWeb,2015,pp.243–246.
- Guo and H. Jin, ‘‘A rule-based framework of metadata extraction from scientific papers,’’ in Proc. 10th Int. Symp. Distribute. Computer. Appl. Bus., Eng. Sci. (DCABES), Oct. 2011, pp.400–404.
- Wang, S. Yu, T. M. Bekele, X. Kong, and F. Xia, ‘‘Scientific collaboration patterns vary with scholars’ academic ages,’’ Scientometrics, vol. 112, no. 1, pp. 329–343, 2017.
- Li, I. Council, W.-C. Lee, and C. L. Giles, ‘‘CiteSeerx: An architecture andWebservicedesignforanacademicdocumentsearchengine, ’inProc. 15th Int. Conf. World Wide Web, 2006, pp.883–884.
